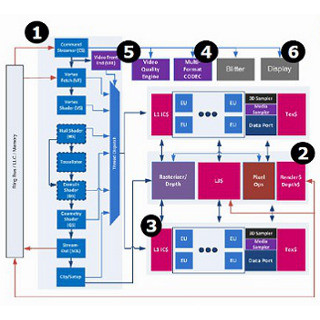
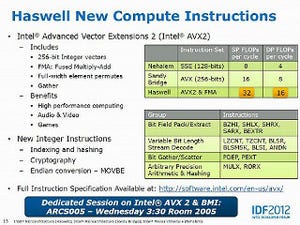
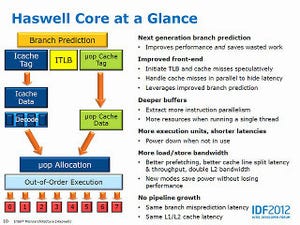
D-Cache/RAM Latency(グラフ79~82)

|
Bandwidthの次はLatencyである。ということでまずグラフ79がForwardのケースであるが、L1は同等。L2は8.2cycle→7.8cycleと微減、L3も9.2cycle→8.5cycleとやはり微減である。グラフからも判る通り、全般的にIvy Bridgeより良好な結果になっている。

|
これはBackwardのケース(グラフ80)でも同じだが、L3では時々Spikeが出て、この際はIvy Bridgeとさして換わらない。またL3 Missでメモリアクセスになると、次第にLatencyが増えている事が判る。

|
このLatencyの増加、Random(グラフ81)では更に顕著になっており、HaswellのL3はIvy Bridgeと比較して5cycleほどLatencyが増えている。

|
Pseudo-Random(グラフ82)では差は2cycleほどに縮まっているものの、Latencyが増えている事は明白である。
L1/L2はここで見る限りHaswellとIvy Bridgeがほぼ同等であるが、L3に関しては規則正しいアクセスでは高速だが、これを外すと遅くなるという傾向は、I-TLBなどでも見受けられたが、ここでもこれが継承されている感じだ。ただ先ほどグラフ23~30で見たI-Cache Latencyに比べるとLatencyそのものは減ってる感じがあるが、これはI-Cacheの場合、直接Load/Storeを行なうわけではなく、CPUのPipeline経由でFetch→Decodeを行なう際のLatencyから判断している関係で、多少オーバーヘッドが加わるのは間違いなく、行ってみれば「生の」Cache Latencyはそれほど悪化していない(というか、ケースによっては高速化されている)と判断できる。