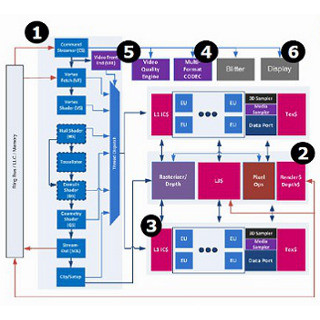
I-Cache Latency(グラフ23~30)
I-CacheのBandwidthそのものは(ちょっとグラフが前後するが)グラフ17でほぼわかったと思う。このケースではμOp Decode Cacheの効果が限定的で、結果、
| |
Ivy Bridge |
Haswell |
| L1 |
32 Bytes/cycle(推定) |
32 Bytes/cycle |
| L2 |
7 Bytes/cycle |
16 Bytes/cycle |
| L3 |
6 Bytes/cycle |
9 Bytes/cycle |
といった帯域になっていると思われる。ちなみにIvy Bridgeは24Bytes/cycleで頭打ちだが、これはSimple Decoder×3だと8×3=24Bytes/cycleが実際にFetchできる上限だからで、要するにDecoder側がボトルネックになっていると考えられるからだ。
話を戻すと、そんなわけで特にL2/L3の帯域は大幅に増強されたことが判ったが、ではLatencyは? ということで今度はこちら。まずNear Jump系だが、Forward(グラフ23)を見るとL1は同等、L2は同等であるが、なぜかIvy Bridgeが早いタイミング(16KB付近)でCache Missを起こすのが不思議だが、それを抜くとL2もほぼ同程度である。L3に関しては、1cycleほどHaswellがLatencyが多くなっている。大きく違うのはMemory Accessで、こちらでは10cycleほどHaswellが悪い結果に終わっている。Backward(グラフ24)も傾向は同じだが、Ivy BridgeはL2~Memory Accessの範囲で「若干」Latencyが増えている程度なのが、Haswellでは急激にLatencyが増えている事が判る。
ただ、Random-Access(グラフ25)ではそれほど変わらないというか、Haswellの方がむしろLatencyが少ないし、Pseudo-Random(グラフ26)でも同じである。
この傾向はFar Jumpの場合も同じで、Forward(グラフ27)はそれほど大きな差がないのに、Backward(グラフ28)になると急にLatencyが激増する。
単にCacheだけでなくMemory Accessでもこれは当てはまる。Random(グラフ29)あるいはPseudo-Random(グラフ30)ではむしろ改善しているわけで、これはもう「そういう風にCache/Memory Controllerを作り変えた」ものと思われる。
Backward Accessがどの程度一般的かと言われれば「全然普通ではない」ので、この程度の性能悪化は許容範囲なのかもしれないだろう。実際、通常多く使われるForward AccessやRandom Accessでは性能が改善しているわけで、おそらくはこちらへの最適化の結果、Backward Accessでは性能悪化という副作用が出たものと思われる。いずれにせよアクセスパターン次第では恐ろしく性能が悪化する場合がある、というのがHaswellの傾向として挙げられそうだ。
次ページ:RMMA 3.8 - I-Cache Associativity