どの程度、ゲームの実行性能が向上したのか?
次の棒グラフは7種のゲームアプリについて、浮動小数点演算の数を1.0に正規化して、整数演算の数がどれだけあるかを示すものである。右端の棒グラフは7種のゲームの幾何平均である。幾何平均で見ると、浮動小数点演算100命令に対して、整数演算は36命令である。
Pascalでは合計136演算命令を実行する必要があるが、Turingでは浮動小数点演算命令と整数演算命令を並列に実行できるようになったため、このケースでは整数演算は浮動小数点演算の陰で実行することができ、(命令間にデータ依存性などの実行制約がない場合は)100演算命令の実行時間で済む。つまり、浮動小数点演算と整数演算の並列実行で36%演算性能が上がることになる。
-
7種のゲームアプリの浮動小数点演算と整数演算の比率。右端の棒グラフは6種のゲームの幾何平均。幾何平均で見ると、浮動小数点演算100命令に対して整数演算は36命令である。したがって並列実行で36%演算性能が上がる

従来のSIMD/ベクタ演算の場合は、次の上側の図のように演算を行っていたが、Turingでは全スレッドで同じデータで同じ計算を行っている場合は、コンパイラとハードウェアアシストで同じ計算であることを検出して、スカラ演算器を使って計算を行うようにしている。このようにするとスカラ演算とメインの演算器を使う並列計算を並行して実行することができるようになる。このため、それらを順次実行するのに比べて短い時間で実行することができる。ForzaのMotor Sports7というゲームでは、このようにスカラ演算器とINT32やFP32演算器を並列に動かすことにより、12.7%実行性能が向上したという。
-
Turingではコンパイラとハードウェアアシストで、多数のスレッドで同じスカラ演算を行っているケースを検出し、その演算をスカラ演算器で行うことができるようになった。つまりスカラ演算器、INT32、FP32演算器のそれぞれを並列に使うことができるようになった。これにより、ForzaのMotor Sports 7というゲームの実行性能は12.7%向上した

次の図は7種のベンチマークプログラムで、PascalとTuringのシェーダーの性能を比較したグラフである。VRMarkでは2倍を超える性能向上になっており、その他の6種のベンチマークでも1.5倍から1.7倍程度の性能向上になっている。
-
PascalとTuringのシェーダー性能の比較。VRMarkでは2倍強、その他のベンチマークでは1.5倍~1.7の性能になっている

INT8とINT4のディープラーニング計算をサポート
TuringではTensorコアが搭載されており、Pascalに比べて8倍のディープラーニング計算スループットとなっており、FP16では114TFlopsのディープラーニング演算を行うことができる。また、TuringのTensorコアではINT8とINT4でのディープラーニング計算がサポートされ、INT8の精度で良い場合は228TOPS、INT4の場合は455TOPSの演算ができる。
-
TuringはTensorコアを搭載し、Pascalの8倍のディープラーニング計算スループットとなった。FP16での計算の場合114TFlopsの演算能力を持ち、INT8では228TOPS、INT4では455TOPSの演算ができる

Turingのディープラーニング計算ではスレッド間でデータの使いまわしを行うことにより、レジスタファイルやシェアードメモリのメモリバンド幅を節約している。また、SMの機能を強化し、各種の活性化関数の実装や、バッチ正規化などの機能をSMに組み込んでいる。
なお、INT8、INT4で乗算を行う場合も、精度の向上のため、その後の加算はINT32で計算を行っている。
-
Tensorコアはスレッド間でデータを共用できるケースでは同じデータの読み込みを省いてレジスタファイルやシェアードメモリのバンド幅を節約する。また、SMと連携して動作でき、フレキシブルに各種の活性化関数を計算することができる。INT4/INT8で積を計算する場合も、精度の向上のため、和の計算は32bit整数で行っている

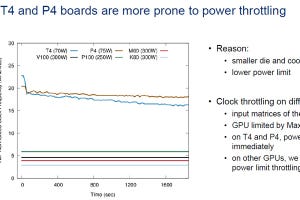
次の棒グラフはCPUサーバとTesla P4(Pascalアーキテクチャ)、Tesla T4(Turingアーキテクチャ)を使った場合の性能を比較したものである。左端のグラフはP4とT4のピーク演算性能を比較しており、T4はFloatでは11.8倍、INT8では5.9倍の性能となっている。また、T4ではINT4がサポートされており、INT8の2倍の性能となっている。
右側の3つのグラフはDeep Speech 2での音声認識、ResNet-50でのイメージ認識、GMNTモデルを使う自然言語処理の性能の比較で、音声認識ではT4はCPUと比較すると21倍速く、イメージ認識では27倍、自然言語処理では36倍速いという結果になっている。
-
TuringはPascalと比べるとFloatによるディープラーニング計算では11.7倍のピーク性能で、整数計算で良い場合はさらに高い性能が得られる。右の3つのグラフはDeep Speech 2を使った音声認識、ResNet-50でのイメージ認識、GNMTモデルを使う自然言語処理の性能で、CPU処理の性能を1.0に正規化したグラフとなっている。PascalではCPUに対してそれぞれ4倍、10倍、10倍の性能であるが、Turingではそれぞれ21倍、27倍、36倍の性能が得られた