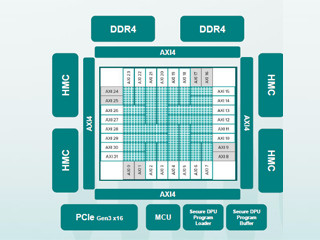
カーネルプログラムの実行は、Quadと呼ばれる4個のプロセサ単位で行われる。スレッドスケジューラは、データ依存性を理解し、スレッドの実行リソースが使用可能で、入力データが使える状態になっているスレッドを選択してディスパッチする。
必要なところでは順序性を維持し、デッドロックを防ぐと書かれている。また、スレッドを纏めたり、スレッドを分割したりするなどの複雑なシナリオもサポートすると書かれているが、詳細な機能については説明されなかった。
なお、この図にみられるように、4つのプロセサを含むQuadという単位が多数個チップに集積されており、さらに、DMAユニットとL2キャッシュ、L3キャッシュが搭載されている。

|
|
GSPにはQuadという4コアのグループ多数とL2、L3キャッシュ、DMAなどが搭載されている。スレッドスケジューラはデータ依存性を理解し、実行リソースが使用可能で、入力データがそろっているスレッドを選択して命令を発行する |
ストリーミングデータではなく、長い期間存在するデータに対しては、GSPは2次元の配列としてアクセスする機能をもっている。このアクセスは任意のアライメントで使えるようになっている。
また、並列のリダクション命令をサポートしており、これにより消費電力を削減し、スループットを増大し、バンド幅を減らすと書かれている。ニューラルネットの計算では、積項の総和を求めるという計算は頻繁に出てくる計算であり、複数の総和計算やそのデータの読み込みを纏めて並列のリダクションとして実行できる場合は、電力の削減やスループットの改善などができることは容易に想像される。
また、2次元のメモリアクセス機能を備えることにより、1次元のベクトルパイプラインと比べて2倍のスケーリングができているという。

|
|
メモリ上のデータはブロックとしてアクセスができる。そしてブロックの位置は任意のアライメントをサポートする。並列リダクション命令を使うと電力や必要なメモリバンド幅を削減して、スループットを増大することができる |
GSPでは、数100のスレッドの中から、実行を開始できる命令を選択するハードウェアの命令ピッカーを持ち、選択された命令を数10の独立のパイプラインに発行することができる。したがって、GSPは高い命令レベルの並列性を持っている。

|
|
命令スケジューラは、数100のスレッドの中から、実行を開始できる命令を選択して、数10の独立のパイプラインに実行を行わせる |
GSPは、扱うデータタイプ、精度、グラフのトポロジなどには一切制約はない。そして、多数のパイプライン化された実行ユニットでグラフを並列に実行する。マシンラーニングのフレームワークとして、TensorFlow、Caffe、Torchが使える。OpenVXとOpenCLが使え、豊富なグラフ作成と実行ができるようになっている。そして、高速化されたカスタムカーネルサポートが拡張されているという。

|
|
GSPは、データタイプ、精度、グラフトポロジなどに制約はなく、完全にプログラマブルである。TensorFlow、Caffe、Torchフレームワークが使える。また、OepnVXとOpenCLも使える |
GSPチップはTSMCの28nm HPC+プロセスで作られており、スタンドアローンのSoCとして使えるモードとPCIe接続のアクセラレータとして使えるモードを持っている。SoCモードの場合の消費電力は2.5W(推定)である。

|
|
GSPはTSMCの28nm HPC+プロセスで作られ、SoCモードでの消費電力は推定2.5Wである。このチップは、スタントアローンのSoCとしても使えるし、PCIe接続のアクセラレータとしても使える |