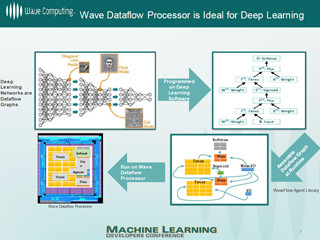
畳み込みネットワークの場合は、1つのニューロン(ノード)が1つのDPUに対応し、1つのDPUは多数のバッチを処理すると書かれている。DLUチップに集積されるDPUの数は公表されていないが、せいぜい1000個程度と考えられ、現在のニューラルネットを構成するのに必要なニューロンの数には遠く及ばない。したがって、1つのDPUはたくさんの処理バッチを切り替えながら処理して、たくさんのニューロンの処理を行う必要があると考えられる。

|
|
Masterと呼ぶ大型コアがメモリアクセスとDPUへの命令供給などを担当する |
DPEは8個の演算を並列に実行するSIMD演算器と大きなレジスタファイルからなっている。それぞれのDPUはたくさんのニューロンの処理を行う必要があるので、それらのニューロンの入力の重みを記憶しておく必要がある。このため、汎用プロセサと比較すると~100倍という巨大なレジスタファイルが必要となっていると思われる。
巨大なレジスタファイルを持ったとしても、全部の重みを保持することはできず、HBM2からレジスタファイルへのデータ転送が避けられない。HBMからレジスタファイルへのデータ転送バンド幅が性能リミットになる可能性があるが、この発表では、この部分の詳細は説明されておらず、どのようになっているのかは分からない。
なお、16個のDPEは単方向のリング接続であり、前の層の処理結果を次の層の入力に送るというディープラーニングの処理をエネルギー効率よく実行できるのではないかと思われる。

|
|
DPEは8SIMDのFP32演算器とCPUの100倍程度と言う巨大なレジスタファイルからなる。DPUは16個のDPEからなり、128演算を並列に実行できる |
DLUは、FP32、FP16×2、INT16×2、INT8×4の形式のデータを扱うことができるようになっている。特に、INT8、INT16データを入力とする場合は、積項の和を求めるときには、入力よりビット数の多いアキュムレータを使っている。
このようにアキュムレータのビット数を増やすことにより、次の図で赤い破線の矢印で示すように実効的な計算精度が向上し、FP32での計算には及ばないが、ディープラーニングに必要とされる程度の計算精度が得られるようになるという。富士通は、このような計算法を「ディープラーニング整数」と呼んでいる。
INT8やINT16のような整数で計算を行うことにより、FP32での計算に比べると、演算に必要なエネルギーは小さくなる。なお、DPEが8並列SIMDというのはFP32の場合で、INT16では16SIMD、INT8では32SIMDとなり、演算/電力は2倍、4倍以上に向上する。これにより、FP32での計算に比べて10倍の演算性能/Wを実現するというのは可能性があると思うが、他社も、このようなアキュムレータの拡張は行っており、競合製品と比較して10倍の性能/電力が達成できるかどうかは難しいところがありそうである。

|
|
INT8、INT16で乗算を行っても、長いビット数のアキュムレータを加算に使えば実効的な演算精度を高くすることができ、ディープラーニングの処理にも使える |
次の図は、横軸が学習の回数、縦軸が認識率を表している。左の図はLeNetで手書き文字の認識の学習を行ったケースで、FP32で計算した場合に比べて、INT16+長いアキュムレータでの計算でも認識率にはほとんど差がない。一方、INT8+長いアキュムレータでの計算では5,000回まではうまく行っているのに、10,000回学習させると大幅に認識率が下がっている。
右の図はVGG16風のネットで、ImageNetの一部の画像の認識の学習を行った場合で、長いアキュムレータを使えば、かなりうまく行っている。しかし、この図には5本の折れ線グラフがあるが、4つしか条件が書かれておらず、折れ線と条件の対応が良く分からない。ということで、筆者の解釈が正しいかどうか分からないが、10,000回の学習の結果では、FP32に比べてINT16+長いアキュムレータの認識率は若干低いように思われる。
Googleの初代TPUではINT8で演算を行い、推論専用であったが、第2世代のクラウドTPUではFP16で演算を行い学習にも使えるチップとした。NVIDIAのVoltaもFP16で計算するTensor Coreを搭載したということで、先行する2社は、学習にはFP16を使うということで一致しており、INT16+長いアキュムレータで対抗できるかどうかには不安が残ると思われる。

|
|
計算精度と学習回数による認識度の改善。左はLeNetによる手書き数字の認識、右はVGG16ライクなネットワークによるImageNetのサブセットの認識の例 |
そして、富士通は、この第1世代のDLUに続いて、第2世代以降も開発を継続する考えである。第1世代はホストCPUを必要とするが、第2世代ではホストCPUをDLUに内蔵する計画である。さらに将来は、本物の神経回路に近い動きをするニューロモルフィックなプロセサや組み合わせ最適化を行う専用プロセサの開発なども視野に入れている。

|
|
富士通のDPUのロードマップ |
結果として、富士通のプロセサ開発は、汎用サーバ向けのSPARC64、スーパーコンピュータ向けのSPARC64 fxシリーズにディープラーニング用のDLUが加わることになる。スーパーコンピュータ向けとディープラーニング向けは要件が大きく異なるので、別個のアーキテクチャのプロセサの開発が必要になると見ている。

|
|
AI向けのプロセサはHPCとは異なるアーキテクチャで独立に開発する |
なお、先行するGoogleは、ディープラーニングに特化した専用のプロセサを開発する構えで、富士通の路線に近い。一方、NVIDIAはVolta V100はTensor Coreを搭載してディープラーニング性能を引き上げるのと同時に、科学技術計算で主流のFP64の演算性能も約40%引き上げるという2正面作戦で1つの製品で両方をカバーするという路線であり、どちらが主流になるのか興味深いところである。