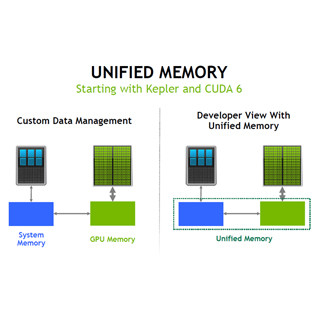
次のグラフは、最大フロー問題を、CPUメモリをNVLINK経由でアクセスするゼロコピーメモリとして使った場合の性能を1.0として、Pascalのユニファイドメモリを使った場合の性能を示している。左の青のグラフは単純に書いたベースラインのプログラムの性能で、右はページの場所のヒントを追加して最適化を行った場合の性能である。
そして、横軸はGPUメモリの容量に対する使用メモリ量の比率で、左の2つはGPUメモリの0.5倍と0.9倍のメモリを使っている場合である。基準値の処理は、これらのケースではGPUメモリで間に合う容量なのに、わざわざアクセスの遅いCPUメモリを使っている状況なので、3倍以上遅くなっている。
右の2つのケースはGPUメモリの1.2倍と1.5倍のメモリ量を必要とする場合で、ベースラインでも1.7倍程度、最適化を行うと1.2倍のメモリ量のケースでは2.6倍。1.5倍のメモリ量のケースは2倍の性能となっている。
しかし、デマンドページが大きな効果を発揮するのは、GPUメモリの数10倍かそれ以上のメモリを必用とするケースで、その場合の性能を知りたいところである。

|
|
CPUメモリをNVLINK経由で使う場合を基準とし、ユニファイドメモリのデマンドページングを使う場合の性能。GPUメモリの1.2倍と1.5倍のメモリを必要とする場合でも最適化すれば、基準値の2倍以上の性能となる |
デマンドページングは便利な機能であるが、オーバヘッドも大きいので、使い方には注意が必要である。
Pascalのユニファイドメモリは、アクセスするデータが存在しないことでページフォールトが発生することにより、メモリのコピーを行っている。しかし、これには10μs以上かかり、その間、GPUの動きは止まってしまう。従って、ページフォールトが発生する頻度を減らすことは性能向上につながる。
また、ページ(4KB)の単位のコピーであり、その範囲のデータは一括してコピーされる。この4KBの範囲のアクセスが多ければ性能が上がる。また、近傍のアクセスが多ければ、コピーするページ数が少なくなり、性能が上がるので、アクセスのローカリティを向上させることも性能向上につながる。
そして、同じページがCPUとGPUの間を頻繁に行き来するスラッシングを起こさないようにすることも重要である。

|
|
ページフォールトの処理には10μs以上かかる。ページフォールトの頻度を減らすことが重要である。そのためには、メモリアクセスに局所性の向上や、スラッシングが起こらないようにすべきである |