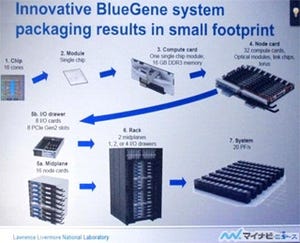
TitanはJaguarのアップグレードでコストを低減
このTitanであるが、これまでのJaguarスパコンの筐体、バックプレーン、インタコネクトのケーブル、電源、液冷の冷却システム、ファイルシステムなどを流用し、計算ノードのボードを入れ替えるというアップグレードで実現されている。ノードボード以外の大部分を流用することにより、全部を新設する場合に比べて2500万ドルの節約になったという。
このアップグレードであるが Phase-1では4672枚のノードボードを古いJaguarのノードボードと入れ替え、さらに、電源やファンを追加するという作業をCrayの工場から作業員が多数出向いて、ORNLのスパコンセンター内で実施している。このCPUとインタコネクトのアップグレードを行った結果が今年6月のTop500で6位となったJaguarシステムである。
そして、Phase-2では、全部のノードボードを、また、筐体から引き抜いて18,688個のK20x GPUを取り付けて筐体に戻すという作業をやっている。 そして、筐体の絵をJaguarからTitanに貼り換え、アップグレードが完了というわけである。

|
|
JaguarからTitanに筐体の壁紙を貼り換え(出典:http://www.olcf.ornl.gov/titan/) |
Titanの液冷システムはJaguarのものを流用しており、約24℃の空気を筐体の下部から取り込み、大型のファンで3段に積まれた24枚のノードボードに吹き上げる。ノードボードの熱を吸収し、空気温度は46℃程度まで上昇する。
この暖まった空気を屋根のように見える部分でR134a冷媒を使った冷却器で吸収して元の24℃に戻して室内に排出している。

|
|
Titan筐体の液冷システム。下部の大型ファンで3段のノードボードを空気で冷却。屋根の部分で、暖まった空気をR134a冷媒で冷却して室内に戻している |
なお、R134aはエアコンなどに使われている冷媒で、配管から漏れても気化してしまうので、水冷のように、漏れて電子部品がやられてしまうということがない。
スパコン本体以外の部分でも、省エネを徹底
京スパコンの場合は、暖まった空気はコンピュータ室の両側にあるダクトを通って下の階に行き、そこで水冷されてコンピュータ室の床下に戻るという長いループとなっているが、Crayの冷却システムは空気を動かす距離が圧倒的に短く、この空気を動かすのに必要な電力が900kW節約できているという。

|
|
Titanでは高電圧での給電や可変速度のチラーの採用、フライホイールを使うUPSの採用などでPUE=1.25を実現 |
また、センターのビルに13,800Vの高圧を引き込み、筐体まで480Vと高い電圧で給電を行っており、電力の割に電流を小さく抑えている。480Vの採用で電線を細くすることにより100万ドル以上コストを削減しているという。また、電流の低減はジュール熱によるロスを減らす効果がある。
ノードボードの発熱を吸収して気化したR134aはチラーと呼ぶ大型の冷凍機で冷やして液化して循環させるのであるが、大型の冷凍機は一定の速度で運転するものが多く、負荷の低い場合にも同じ電力を消費してしまう。これに対してTitanでは可変速度のチラーを使い、負荷に応じて冷却能力を可変してチラーの消費電力を抑えている。
また、UPS(無停電電源)はバッテリーに電気を蓄えておくタイプではなく、高速回転するフライホイールに運動エネルギーを蓄え、停電の場合には、フライホイールが発電機を回して電力を供給するというタイプのものを使っており、こちらの方が効率が高いという。
結果として、PUE=1.25(冷却に必要な電力やロスを含むセンターの消費電力がコンピュータ自体の消費電力の1.25倍)を実現しているという。寒冷地にあるデータセンターなどでは外気による冷却を使って、より低いPUEが報告されているが、テネシー州という米国南部にあるセンターとしては、低いPUEとなっていると言える。
K20x GPUの効果
K20x GPUが増設されたのが、今年6月のJaguarから11月のTitanに変わったポイントであり、これにより、LINPACK性能としては1.941PFlopsから17.59PFlopsと9倍に向上している。しかし、実アプリケーションでどれだけの性能向上が得られるかが問題であり、講演ではGPU増設の効果として次のスライドが示された。

|
|
Early ScienceのアプリケーションのGPUによる性能向上。K20x GPUの追加により1.8~7.4倍の性能向上 |
それによると、S3DやCAM-SEでは1.8倍の性能向上となっている。この程度だと、GPUの増設でなく、そのボードスペースを使ってCPUを倍増した方が得かも知れないという感じであるが、Denovo Sweep、WL-LSMSでは3.8倍、LAMMPSでは、単精度演算も組み合わせた結果であるが、7.4倍の性能向上が得られており、これらのアプリケーションではGPUの追加は効果的である。また、この結果には「Very Early」と断り書きがあり、今後のチューニングにより、さらに効果が高まる可能性がある。
巨大システムの大きな懸念は信頼性であり、講演後の質疑で故障率に関する質問がでた。これ関して、講演者のBland氏は、1日あたり3~4台のノード故障があるが、システム全体のダウンは数日に1回程度と回答していた。この状況では、全ノードを使うLINPACKで24時間程度かかる規模の計算を行っても、途中でどれかのノードが故障して計算を完了できないと思われる。これが今回のTop500では、GPUメモリだけを使って1時間弱のLINPACK計算に留めた理由ではないかと思われる。
6月のTop500ではCPU側のメインメモリを使って長時間のLINPACK計算が出来ていた筈であり、CPU側の故障率はそれほど高くはないということになる。とすると、故障の大部分は増設されたNVIDIAのK20x GPUで発生している推定される。このノード故障が減り、無故障で24時間程度かかる計算が可能になれば、Titanも京コンピュータやSequoiaのように、CPU側のメインメモリも使った問題サイズの大きいLINPACK計算を行って、次回以降のTop500でより高いLINPACK値を出してくる可能性がある。