東工大のTSUBAME2.0システム
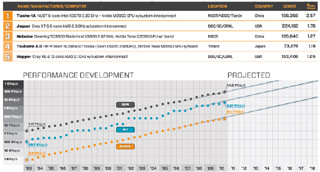
今回のTop500で、東工大のTSUBAME2.0は1.192PFlopsを達成し4位となった。前回、2010年6月のTop500での日本のベストが23位という状況から大きくランクを上げ、日本の面目を保ったといえる。
しかし、ピーク性能が2.29PFlopsに対して1.192PFlopsのLINPACK性能は、ピーク比52.1%である。東工大はTSUBAME1.2の頃からNVIDIAのGPUを使い、遠藤准教授や額田研究員などLINPACKのGPUスパコンへのチューニングでは国内トップレベルの人材を持ち、今回はテキサス大学からマイクロソフトに移った後藤氏(後藤BLASを開発し、LINPACKのチューニングでは世界的に有名)も参加したマイクロソフトチームと人材的には世界最強とも言えるチームで頑張ったが、星雲システムの1.271PFlopsを抜くことはできなかった。

|
|
東工大ブースで椅子に座ってノートPCを操作しているのが遠藤准教授で、講演をしているのが額田研究員 |
東工大のTSUBAME2.0システムも天河一号Aシステムと同様にIntelのX5670をCPUとして使用し、NVIDIAのM2050 GPUをアクセラレータとして使用している。しかし、天河一号Aが2CPUに1GPU接続の計算ノードを使用しているのに対して、TSUBAME2.0では2CPUに3GPU接続という計算ノードとなっており、GPUに対するCPUの比率は1/3である。
遠藤准教授によると、このCPUの量の差は天河一号Aの53.3%と、TSUBAME2.0の52.1%というピーク性能比率に効いているのではないかとのことである。また、1カ月程度の準備期間の間は1000ノード規模で使うことができたが、TSUBAME2.0のフルノードでのLINAPCKの測定は4日しかなく、チューニングに掛けられる時間が不足であった。時間があればもう少し頑張れたのではないかとのことであった。
天河一号AではQDR ×4の2倍のバンド幅のインタコネクトが各計算ノードに繋がっているという構成になっていると思われるが。TSUBME2.0ではQDR ×1のリンクが各計算ノードから2本となっている。これが正しいとすると、TSUBAME2.0の各計算ノードは2.57倍のピークFlopsに対して1/4のインタコネクトバンド幅しか持っていない。ということで、ピークFlopsの大部分を占めるGPUに対するCPUやインタコネクトとの比率を見ると、天河一号AはTSUBAME2.0に比べてかなりリッチな構成である。天河一号Aの建造費用は70億円程度と発表されているが、TSUBAME2.0は半分弱の費用であるのでやむを得ないと言える。
一方、消費電力あたりのLINPACK性能を見ると、TSUBAME2.0が852.3MFlops/Wであるのに対して、天河一号Aは635.1MFlops/Wと、GPUに対するCPUやインタコネクトが少ない分、東工大の方が高性能になっている。
Blue Gene/Qと京コンピュータ
今回のTop500では、115位にBlue Gene/Q(BG/Q)のプロトタイプがランクインした。8,192コアで65.347TFlopsという性能であるが、1チップ16コアであるので512チップという小規模なシステムである。しかし、小規模であるので、消費電力も38.8kWと少なく、LINPACK性能/電力は1684MFlops/WとTSUBAME2.0のほぼ2倍の電力効率となっている。
そして、170位にランクされた京コンピュータは3,264コア、48チップというシステムで48.03TFlopsを達成している。消費電力は57.96kWとなっており、829MFlops/Wである。
Blue Gene/QプロセサもSPARCF64 VIIIfxプロセサも各コアの浮動小数点演算幅を256ビットに拡張しているが、GPUのように制御回路を削って並列演算性能を強化したプロセサではなく、汎用プロセサである。ピーク比率が高いことと合わせて、このような汎用プロセサでも省電力設計を徹底すればGPUを多用するヘテロジニアスシステムと同等のLINPACK性能/電力を実現できることを示している。
これらのシステムはどちらもラック1/2本分のハードウェアであり、ほぼ同じサイズの体積でBG/Qの方が1.36倍の性能を66.9%の電力で実現しているという計算になる。ただし、これはLINPACKだけの比較であり、今後、実用的なアプリケーションの性能がどうなるかを見て行かなければ優劣は判定できない。