TSUBAMEスパコンは成長を続ける
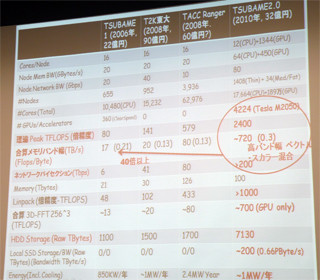
TSUBAME2.0は2010年11月には稼働を始める予定で、松岡教授はさらに先を見ている。2012年ころにはInfiniBandはQDRから転送速度2倍のEDRになり、PCI ExpressもGen3サポートが一般化する。そして、メモリもDDR4が視野に入ってくる。これらのテクノロジを利用した計算ノードを追加して、ピーク演算性能11~14PFlopsに増強する「TSUBAME2.5」の基本設計はすでにできているという。
さらにその先には、2014年から2015年の始めころに「TSUBAME3.0」を計画しているが、演算性能に比べて向上ペースの遅いインタコネクトバンド幅やメモリバンド幅の問題をどう解決するか、規模の拡大にともなう信頼度の確保、そして、さらなる省電力を達成する冷却や管理の自動化をどうするかなど、現在はテクノロジスタディーを行っている状況という。また、省電力、管理の自動化などの分野では、6月16日の記者会見で発表された東工大、北大、国立情報学研究所の「スパコングリーン化技術の大規模実証研究」の成果も取り入れられると予想される。
Top500はどうなるのか
TSUBAME2.0の消費電力は約1MWと、中国の星雲システムの2.55MWと比較すると非常に少ない消費電力であるが、東工大のセンターでは、現在運用中のTSUBAME1.2とTSUBAME2.0を同時に動かすと電力不足になってしまう。このため、2010年8月の後半から現用のTSUBAME1.2の規模縮小を始め、それと並行して9月頃からTSUBAME2.0の計算ノードの設置が始まる予定である。そして10月には全ノードを設置してLINPACKの測定を行い、11月初めにTop500に値を登録するというスケジュールである。
気になるのはLINPACK値がどうなるか、特に、同じようにIntelのWestmere-EP CPUとNVIDIAのTesla 20 GPGPUを使う中国の星雲システムとの関係がどうなるかである。星雲は2個のWestmere-EP CPUに1台のC2050ボードを付けた計算ノード4640台から構成されており、ピーク性能2.98PFlosであるが、LINPACKでは1.271PFlopsとピークの42.6%しか出ていない。LINPACKの主要な計算は行列積の計算であるが、松岡教授によると、現在のFermiボード単体では行列積はピーク性能の70%近い値が出ているという。
そして、CPU-GPU間のデータ転送やノード間のデータ転送などがすべて見込み通りの性能で、予期しない問題が出なければ、LINPACKでピーク性能の60%程度の値が出せる可能性があるという。しかし、このような大規模システムはやってみるまでどこで問題が出るか分からない。動作開始からLINPACK値の測定、チューニングを繰り返して、Top500への登録まで1カ月程度という短い期間であるので、目論見通りの性能を出せるかどうかは、やってみなければ分からないという。
ピーク性能の60%を出すことができれば単純計算では1.44PFlopsとなり、日本初のペタフロップス(PFlops)超スパコンとなる。そして、Top500首位のJaguarの1.759PFlopsには及ばないが、2位の星雲システムを上回ることになる。東工大チームの幸運を祈るとともに、その頑張りに期待したい。