2010年6月16日、東京工業大学(東工大)は、同大学の学術国際情報センター(GSIC)に設置する次期スーパーコンピュータ「TSUBAME2.0」に関する記者会見を行い詳細を発表した。東工大はTSUBAME1.0で38.18TFlopsを達成し、2006年6月のTop500で第7位にランキングされ、その後、GPGPUなどの増設で能力強化を行ってきたが、現在(2010年6月のTop500)は87.01TFlopsで64位(国内6位)となっている。
最初のTSUBAME1.0の設置から4年を経過し、今年は全面更新を行う。これがTSUBAME2.0である。
TSUBAME2.0は高性能、ローコスト
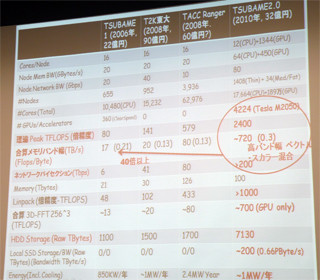
現在のTSUBAME1.2のピーク演算性能は163.2TFlopsであるが、新システムのピーク演算性能は2.4PFlopsと約15倍に向上する。現在、国内トップのスパコンはJAEA(日本原子力開発研究機構)の200TFlopsのシステムであるので、ピーク性能だけで言うと12倍というぶっちぎりの性能である。これで4年間の保守費を含めた調達費用は32億円で、建物の改装費用や4年間の電気代などを含めても計40億円程度という規模の割にローコストなシステムである。
このような性能と費用を実現できた理由は、国内初のCUDA Center of Excellenceになったように、メーカーとの共同研究などで単なる購入に比べて大幅に安い価格を引き出す松岡聡教授の交渉力(と裏付けとなる東工大チームの研究開発力)に負うところが大きいと思われるが、技術的にはNVIDIAのFermi GPGPUを採用したことが大きく効いている。TSUBAM2.0の2.4PFlopsのうち、2.18PFlopsがGPGPU分で、CPU分は206.7TFlopsである。GPGPUはFlopsあたりのコストが安いので価格が抑えられるのは当然であるが、CPU分だけでもJAEAのシステム規模をわずかながら上回り、これで32億円は割安である。
2CPUと3GPUを搭載する計算ノード
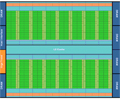
TSUBAME2.0システムの中核をなす計算ノードはHP製で、6コアのWestmere-EP CPU 2ソケットというのは普通であるが、I/Oまわりが一般のサーバとは異なる。普通は、1個のTylersburg IOHを2個のCPUで共用するが、TSUBAME2.0の計算ノードは、IOHを2個付け、2個のCPUと2個のIOHはQPIでリング状に結合されている。IOH 2個で合計72レーンのPCI Express2.0をサポートすることができるので、3枚のTesla M2050ボードを3枚とQDR InfiniBandのHCAを2枚、さらにSSDを接続するというI/Oリッチな構成が可能になっている。
GPGPUは演算性能が高いだけでなく、GDDR5メモリを使うことにより、高いメモリバンド幅を持っている。その結果、合計のメモリバンド幅は0.72PB/sであり、0.3Byte/FlopのB/F比を保っている。

|
|
TSUBAME2.0の計算ノードの構成 |
Westmere-EP CPUのクロック周波数は2.93GHzで、計算ノードは52GiB、あるいは96GiBのDDR3-1333メモリを搭載している。2種類のメモリサイズがあるのは、大きいメモリを必要とするジョブとそうでないジョブがあるので、それにきめ細かく対応するためである。
また、この図には書かれていないが、各計算ノードはSSDを搭載している。メモリが52GiBのノードは60GBのSSD 2台、96GiBのノードは120GBのSSD 2台である。このSSDは、実行途中の状態をチェックポイントとして書き出すという用途をメインに考えているので、メモリ量で、SSDの容量に差がついている。もちろん、このSSDはチェックポイントだけではなく、通常のスクラッチパッド的なファイルとしても使える。
この計算ノードは既製品ではなく、東工大がHPと協力して開発を行ったものであるという。M2050 GPGPUボードはNVIDIAの標準製品であるが、秋葉原で売られているFermiを使ったグラフィックスボードとは全然違うという。松岡教授によると、使っているFermiチップは同じであるが、出荷試験の厳しさが違う。また、グラフィックス用はメモリのECCが無いのに対して、科学技術計算用のTeslaボードではECCがサポートされエラー訂正を行うことができる。
さらに、Teslaではメモリクロックを下げており、ECCと併せてメモリバンド幅は減っているが、メモリの安定度が全然違う。グラフィックスボードではメモリテストを流すとかなりエラーが出るが、Teslaでは安定しているという。そして、グラフィックスボードや中国の星雲が採用したC2050ボードはボードに小型のファンが付いているが、TSUBAME2.0で使うM2050は大きな放熱フィンが付いているがファンはなく、サーバのファンで冷却する構造になっている。小型で高回転数のファンはベアリングの摩耗が早く故障しやすい部品である。一方、サーバ本体は2連ファン構成などで1個のファンが故障しても運用を続けられるようになっているので、サーバ側のファンで冷却するM2050は信頼度が違う。この辺にも、GPU使用経験の長い東工大と中国の違いを感じるところである。