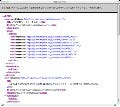
habuを使うには、まず「habu.cfg」という名前で設定ファイルを編集します。設定ファイルはPlaggerと同様にyaml形式を採用しています。なお、現在配布しているtarボールには、サンプルとして次のような内容のhabu.cfgを同梱しています。
global:
timezone: Asia/Tokyo
log: stdout
pipeline:
rss_fetcher:
- module: subscription.config
config:
feed:
- http://www.liris.org/blog/RSS
- http://dev.ariel-networks.com/Members/blog_update/RSS
- module: filter.join
- module: filter.sort
config:
reverse: True
- module: publisher.rssfeeder
config:
file: "out.rss"
このサンプルでは、複数のサイトからRSSファイルを取得して、日付でソート後1つのファイルにしています。これをコマンドラインから実行してみます。
$ python runhabu.py
正常に実行されると、カレントディレクトリにout.rssというファイルが生成されます。
次に、このRSSから、本文中にpythonという単語が書かれているエントリだけを抜き出してみます。次の内容で「python.cfg」を作成してください。
global:
timezone: Asia/Tokyo
log: stdout
pipeline:
rss_fetcher:
- module: subscription.config
config:
feed:
- http://www.liris.org/blog/RSS
- http://dev.ariel-networks.com/Members/blog_update/RSS
- module: filter.join
- module: filter.grep
config:
str:
summary: python
- module: filter.sort
config:
reverse: True
- module: publisher.rssfeeder
config:
file: "out.rss"
habu.cfgからの変更点は、moduleの「filter.grep」を追加しただけです。プラグインは「チェーン」になっており、チェーンのフィルタプラグインを変更することでデータを加工します。
これを実行するには、
$ python runhabu.py python.cfg
と入力します。今度は、out.rssの中の各エントリは「python」という文字列が含まれているものだけになりました。
プラグインのチェーンは1つだけではなく、pipelineの中に複数指定できます。今回のpipelineではrss_fetcherというチェーンしかありませんが、複数のpipelineを指定すると一気に複数RSSを取得し、加工することができます。
また、サンプルの設定ファイル「cron.cfg」にあるように、schedulerを指定して実行すると、デーモンのようにプロセスが常駐し定期実行できます。
なお、プラグインの種類や各プラグインの使い方、作り方のドキュメントは残念ながらまだありません。「ソースを読め」という思想を持っているわけではないので、用意できるまでもうしばらくお待ちください。
habuの今後
多くのUNIXツールはプログラマ向けのソフトウェアです。現状では、設定ファイルを直接編集する必要があるなど、habuもプログラマやギークを意識した作りになっています。また、まだフィルタなどプラグインの種類が少ないなど機能不足な点は否めないので、しばらくは基本機能の充実が目標です。
その後将来的には、
- サーバー機能の搭載(RSSを再配布できる仕組みの提供)
- グラフィカルな設定ツールを提供
- Windowsとの親和性(サービスへ登録やインストーラなど)
を考えています。特にサーバー機能では、WebだけでなくIMAPやIRCなどでも気軽に情報が取り出せるようにしたいですね。