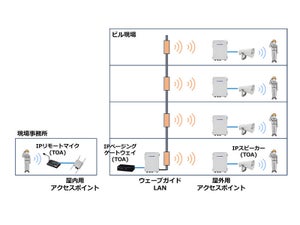
性能差は10倍以上か
さて、この2つの実際の性能差はどの程度かということに対して、いくつかの結果が示されている。TEST AとTEST Bという2種類のベンチマークを用意し、それぞれをS08とColdFire V1で実施した結果が図23に示すものだ。TEST Aは図24のように単純なものである。これはCPUコアとRAMの間だけで処理が済む類のものだから、外部の環境などにはほとんど影響を受けない。結果は図25の通りで、コード密度は概ねColdFireが2倍、性能はColdFireが0.8~3倍といったところだ。
 |
図23 TEST AはともかくTEST BをS08でやるのはちょっと辛い気がする。とはいえ、ニーズとしては間違いなく存在する類のテストだが |
 |
 |
図24 このテストでは、もっぱらSRAMのアクセス速度と演算性能それ自身が律速段階になる |
図25 なぜか表やグラフには"CFV2"とある。"CFV1"のTypoだろうとは思うのだが |
やはりS08で16/32ビットの演算を多用するとコード密度が下がるのは否めないということだろう。ただ8ビットに関して言えば、S08の方がむしろ高速なのは妥当とはいえちょっと面白い。一方、TEST Bの方はもう少し処理が複雑である(図26)。面白いのは、このテストでプログラムサイズはむしろS08の方が小さいことだ(図27)。ただ、実際の演算性能を比較すると、これはColdFire V1の方が圧倒的に高速である(図28)。8ビット演算ですら1.2~2.9倍、32ビットになると10倍以上の性能になっており、両者の性能差としては妥当なところではないかと思う。
 |
図26 10KバイトのテーブルとなるとRAMには置けないからフラッシュメモリ上に置くことになる。となると、これに関してはフラッシュメモリのアクセス速度が律速段階になりそうではある。ただS08ではペーングウィンドウを切り替えてアクセスという形になるから、やはり不利なことは間違いなさそうだが |
 |
 |
図27 数字の下の言い訳がちょっと面白い |
図28 なぜかTEST Bの実行結果が無いのが残念である。こちらを実施すればさらに大きな差が出た可能性がある |
図29はTechnology Labで展示されたFlexisのデモの評価であるが、このテストでは3軸加速度センサが付いた評価ボードにS08とColdFire V1を差し替えながら動かし、
- 3軸加速度センサが出力した生データを読み出すだけ
- 生データから角速度を計算する
- 生データにIIRフィルタを掛ける
という3種類の動作を行わせて、その際の負荷を表示させたものである。
 |
図29 Technology LabではCPUのサイクルそのものではなく、CPUの負荷という形で表示された。S08でIIRフィルタまで実装すると負荷が70%を越えていたのに対し、ColdFireは負荷がほぼ0%のままだった |
S08の場合、生データの読み出しだけだと高速だが、角速度の検出やIIRフィルタを実装すると猛烈に負荷が増えることが分かる。一方のColdFire V1ではほとんど負荷が増えない。このあたりも、やはり性能差が10倍以上あることを体感させてくれた。
このFlexis、「ColdFireで動くようなアプリケーションをS08に移植」という観点で見ると上手くいかないだろう。あくまで「S08で動く8ビットアプリケーションをよりパワフルに実行できる」という使い方が正しいと思う。今は性能差が10倍以上あってギャップが大きいが、今後はRAMやフラッシュメモリの容量、動作速度などを落とした低価格品のバリエーションが増えるそうで、こうなると性能差はもう少し縮まり、選択の余地が増えると思われる。
ところで世間一般には、むしろ16ビットMCUのラインナップを強化する方向にトレンドが動きつつある。ルネサス テクノロジやNECといった多くのMCUベンダが16ビットMCUのラインナップを増やしつつある中で、あえてFreescaleが16ビット品をパスして32ビット品に飛ぶという方針は非常に興味深い。Freescaleも自動車向けに16ビットMCUであるS12シリーズといったMCUをラインナップしているが、こちらをFlexisに統合する計画は今のところないそうだ。したがって今後はFlexisとS12という2本柱で製品が提供されていくことになる。以前にColdFire V4eの発表を聞いたときに「ColdFireは何を目指しているのだろう」と思ったのだが、ここに来てやっとColdFireの方向性が明確に定まった気がする。今後の製品展開が楽しみである。