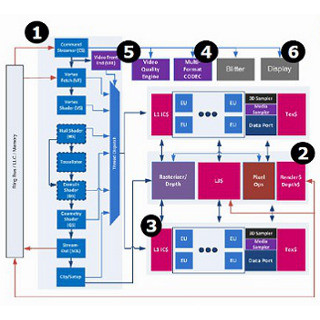
Average RAM Latency(グラフ89~92)
次はRAM AccessのLatencyである。Ivy BridgeにせよHaswellにせよL3が8MBあるので、グラフの左端は事実上L3のLatencyであり、右端がMemoryのLatencyということになる。
さて、まずForward(グラフ89)を見ると、微妙にHaswellの方がLatencyが少ないという見方になるが、それよりもグラフのカーブが綺麗な事の方が重要に筆者は思える。Load/Storeをメモリに対して行なう場合、Ivy Bridgeの様に多少ギクシャクするのが普通で、Haswellのそれはちょっと整いすぎである。Load Bufferが相当大きめで、かつ複数のLoadをOutboundで発行・完了できる環境だとグラフは比較的整いやすいが、Haswellはまさしくそういうことなのだろうと思う。以前示した用にHaswellではIn-Flight Load/Store共にバッファサイズが増やされているが、これに加えてLoad/Storeの同時処理のアルゴリズムも改善されたということだろうか?
ただ、Backward(グラフ90)では多少ギクシャクが目立つようになっており、完璧とは言えない様だ。これがRandom(グラフ91)とかPseudo-Random(グラフ92)になると明確にHaswellの方がLatencyが大きくなっており、このあたりはHaswellのLoad Unitのインプリメントがシーケンシャルアクセス(それもForward方向)に最適化を進めた副作用ではないかと筆者は考える。
次ページ:RMMA 3.8 - Minimal RAM Latency 8MB