文書に含まれる全角文字の前後を「★」で囲む
文書とは別に全角英数字を使っている場合、先の正規表現ですと、すべてがマッチしてしまうため芳しくありません。そこで"全角英数字が全角平仮名や漢字にはさまれている場合のみ"にマッチする正規表現を紹介します。
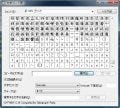
単純に考えれば、全角英数字をあらわす「[0-9A-Za-z]+」を、すべての全角文字(JIS X 0208:1993)をあらわす「[□-黑](※□は全角スペース)」で囲めばいいように思えますが、それでは前後の文字列も検索対象に含まれてしまうため、そのままではうまくいきません(図6)。
 |
図6 検索文字列を「[ -黑][0-9A-Za-z]+[ -黑]」とした場合、全角英数字前後にある全角文字もマッチしてしまいます |
正規表現
検索:[、-◯ぁ-黑]\f[0-9A-Za-z]+\f[、-◯ぁ-黑]
置換:\0★\1★\2
この場合、全角英数字を除く全角文字の指定をブラケットで行なう必要があります。ここでは「、」から全角英数字の直前である「◯」と、全角平仮名の先頭である「ぁ」から「黑」までを「[、-◯ぁ-黑]」と囲みましょう。また、検索用タグをとして全角英数字をあらわすメタ文字の前後に挿入します(ユニコードの場合はバックナンバーをご参照ください)
具体的には検索文字列を「[、-◯ぁ-黑]\f[0-9A-Za-z]+\f[、-◯ぁ-黑]」とします。置換文字列を「\0★\1★\2」とすれば、「\0」は全角英数字の直前にある全角文字、「\2」は直後にある全角文字、「\1」は全角英数字が代入されるため、そのまま置換可能になります(図7)。
 |
図7 前後に全角平仮名などがある文書中の全角英数字は「★」で囲まれますが、1行目にある全角数字はそのままです |
阿久津良和(Cactus)