Googleは、2016年5月のGoogle IOでTensor Processing Unit(TPU)を初めて発表したが、2017年のGoogle IOでは第2世代となる「Cloud TPU」を発表するという急ピッチの開発を続けている。初代のTPUは、自社のデータセンタでの急増するAI関係の負荷を捌くために、必要に迫られて開発したという感じであるが、今年、発表されたCloud TPUは、これを武器に自社センタのサービスを差別化するだけでなく、クラウド上で一般ユーザがTPUを使うというサービスの販売も視野に入れていると思われる。
Tensor Processing Unitとは?
1つの量を表すのが「スカラ」、スカラが並んだものが「ベクタ」、ベクタが並んだものが「テンソル」である。
ニューラルネットの計算では入力ベクタにそれぞれの重みを掛けて合計をとるという計算が主になる。この計算はベクタの積であるが、画像の処理では入力が2次元の行列であることが多い。また、ニューラルネットの各層は多数のニューロンからなっており、ニューロンごとに重みが違うので、重みも2次元の行列になっている。このため、ニューラルネットの計算は、行列と行列の積の計算となる。
行列はベクタの並んだもので、テンソルである。ニューラルネットの計算では、テンソルを入力として、その積を計算するので、Googleはこの計算を行うプロセサをTensor Processing Unitと呼んでいる。
N要素のベクタの積和を計算する場合は、2N個の要素をメモリから読んで、N回の積とN回の加算を行う。これに対して、N行N列の行列の積を計算する場合は、2N2の要素をメモリから読み、N3回の積と和の計算が必要になる。つまり、ベクトルの場合はメモリアクセスの回数と演算の回数は同じオーダであるが、テンソル(行列)の場合は、N2のオーダのメモリアクセスでN3のオーダの計算ができる。
現代のLSIでは、演算器を増やすのは比較的簡単で、メモリアクセスの方がリミットとなるのが普通であるので、メモリアクセスの比率が少ないテンソル演算を行う方が高い性能を出しやすい。また、メモリやレジスタファイルをアクセスする回数が少なくなるので、演算あたりの消費エネルギーも少なくできる。
これがGoogleがTPUを開発し、NVIDIAのVolta GPUもTensorコア演算器を搭載した理由である。
Googleの第1世代TPU
2016年5月のGoogle IOにおいて、Googleは第1世代のTPUを発表した。この第1世代TPU(以下ではTPU1と呼ぶ)は28nmプロセスで作られるASICで、テンソルの積を計算する64K個の積和演算器のアレイを持っている。この積和演算器は毎サイクル、積と和を1回ずつ計算することができ、クロックは700MHzで動作するので、2演算×65,536×700M=91,750M演算/sの性能となる。これをGoogleは92Teraops/sを称している。
TPU1では、ハードウェアの物量を小さくするため、この積和演算器は8ビット整数(INT8)で演算を行っている。ニューラルネットの計算では、入力値の正規化などを行うので推論の場合は8ビット精度の計算でも使えるのであるが、学習には精度不足である。このため、学習にはGPUなどを使いTPU1は推論専用という位置づけになっている。
しかし、TPU1の開発の狙いは、データセンタに押し寄せる大量の推論(画像認識や音声認識など)を効率よく捌くことであり、推論専用で目的は満たしている。
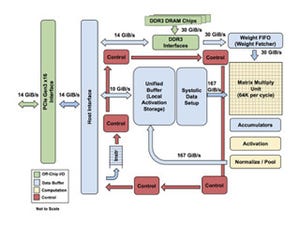
次に示すのが、Googleが発表したTPU1のブロック図である。右端の2番目に描かれた行列積ユニット(Matrix Multiply Unit)が64K個の積和演算器のアレイである。そして、ブロック図の上側に重みの値を記憶するDDR3 DRAM(これはオフチップ)、DDR3インタフェース、重みFIFOがあり、行列積ユニットに重みデータを供給する。
ブロック図の中央に24MBのUnified Bufferというオンチップのメモリがあり、ここからSystolic Data Setupというブロックを通して、行列積ユニットに入力データを供給する。そして、行列積ユニットの出力は256要素×4K行のアキュムレータに格納される。行列積ユニットは最大256×256の行列の積を計算できるが、より大きな行列の場合は、分割して計算を行い、このアキュムレータで足し合わせて大きな行列の積を作り上げる。
そして、行列積の値はReLUなどの非線形の関数の計算を行うアクティベーションユニットと正規化やプーリングを行うユニットを経由してUnified Bufferに書き戻される。Unified Bufferの内容は、次のニューロン層の入力として使われたり、ホストインタフェースを通してホストCPUに送られたりする。
なお、重みデータの供給系は30GB/sのバンド幅を持ち、Unified Bufferと行列積ユニットの間は167GB/sのバンド幅となっている。

|
|
Google TPU1のブロック図 (特に断った図以外の図は、Googleの論文やブログに掲載されたものの引用である) |
TPU1は、ホストメモリからの読み込みやホストメモリへの書き出し、重みの読み込み、行列積の計算、アクティベーション関数の適用などの比較的少数の種類の命令を実行することができる。TPU1の実行する命令はホストCPUからホストインタフェース経由で供給され、命令FIFOに格納されて、順に実行されていく。
TPU1がメモリに格納されたプログラムを実行するのではなく、CPUから供給される命令を順次実行するというコプロセサ的な制御としたのは、TPU1側では命令フェッチや条件分岐などの処理を行う必要なく、構造を簡単にすることが出来るからであるという。
(次回は6月23日に掲載します)