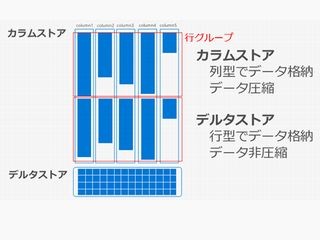
これまでSQL Data Warehouseの概要やアーキテクチャ、オブジェクトの種類などを説明してきました。今回からは、もう少し本番の運用に近い部分、SQL Data Warehouseの「チューニング」に焦点を当て、実際のSQLのチューニングの例を交えて解説していきます。
準備環境
まずは、データベースのベンチマーク環境である「TPC-H」環境をSQL Data Warehouseで用意し、TPC-Hのクエリを中心にチューニングを行っていきます。今回は合計8テーブル、計1000GB(約1TB)のTPC-H用のデータをSQL Data Warehouse上に用意しました。各テーブルの件数は以下の通りです。
| テーブル名 | 件数 |
|---|---|
| CUSTOMER | 150,000,000 |
| LINEITEM | 5,999,989,709 |
| NATION | 25 |
| ORDERS | 1,500,000,000 |
| PART | 200,000,000 |
| PARTSUPP | 800,000,000 |
| REGION | 5 |
| SUPPLIER | 10,000,000 |
※すべてクラスタ化列ストアインデックスで構成、すべてラウンドロビン分散で構成
対象のSQL
TPC-Hでは22本のクエリが用意されています。今回対象のクエリは1番目のクエリとなります。
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count_big(*) as count_order
from
lineitem
where
l_shipdate <= dateadd(dd, -90, cast('1998-12-01' as datetime))
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
実行計画を取得
データベースの運用管理においてSQLチューニングの経験がある方は、実⾏計画(クエリープラン)を確認してチューニングを⾏ったことが多いのではないでしょうか。
もちろん、SQL Data Warehouseでもチューニング対象のSQLの実行計画を確認できます。SQL Data Warehouseでは「EXPLAN」というステートメントが用意されています。対象のSQLの実行計画を、EXPLAINを使って確認してみましょう。確認結果はXML形式で出力されるため、ファイルなどに保存し、XMLエディタなどで確認すると見やすくなります。

|
上記が実際のプランです。赤枠で囲った部分がTotalコストを表しています。約3448がTotalコストです。これに対して、次は処理のどの部分でコストが大きいのかを確認します。青枠の中を確認すると、「SUFFLE_MOVE」というオペレーションがこのSQLのコストの大部分を占めていることがわかります。
SUFFLE_MOVEという動作は、ディストリビューションに分散され配置されているデータを特定の列で再びハッシュ計算し、再配置を行う処理です。
今回のSQLは1つのテーブルのみをSELECTしており、テーブルの結合は行っていません。ただし、group by 句でl_returnflag列とl_linestatus列でグループ化しています。group by でグループ化を行う場合には、SQL Data Warehouseでは各計算ノードでデータのグループ化を行います。
各計算ノードでグループ化を行うには、グループ化を行う列で各計算ノードにデータが配置されている必要があります。配置されていない場合は、特定の列で再配置を行います。これが、「SUFFLE_MOVE」です。
チューニングの落とし穴
先ほどの実行計画の確認で、「SUFFLE_MOVE」で大量のコストがかかっていることがわかりました。さらに、それはl_returnflag列でのディストリビューションの再配置で発生していることがわかりました。では、l_returnflag列をハッシュキーにしたハッシュ分散を行えばいいのでしょうか?
結果は上図の通り、l_returnflag列をハッシュキーにしたハッシュ分散を行ったテーブルのほうが実行時間は約3倍に延びてしまいました。この原因は各ディストリビューションに格納されているデータの偏りです。
ハッシュキーに指定すべき列はカーディナリティの高い列です。l_returnflag列は「A」「R」「N」の3つしかデータが存在しておらず、約60億のデータが60のディストリビューションの中の特定のディストリビューションに極端に偏ってしまいます。SQL Data Warehouseには60のディストリビューションが存在しているのに、実際は3つのディスとビューションしか使えておらず、3つのディストリビューションからの読み取りに非常に時間がかかってしまい、処理が遅くなっています。
今回の例では、当初コストがかかっていたSUFFLE_MOVEをなくすために、特定の列(l_returnflag列)でハッシュキーを設定しました。しかし、設定した列のカーディナリティが低すぎるあまり、逆に60のディストリビューションを効率的に使えず、処理全体が遅くなるという事象に陥りました。データの偏りは以下のSQLで確認できますが、およそ10%程度の偏りがある場合は見直しを考えたほうがよいでしょう。
DBCC PDW_SHOWSPACEUSED('<テーブル名>');
正確にチューニングするには、実行計画だけでは判断せず、テーブルにどのようなデータが入っているのか、どのような分散方式が最適なのかの確認にも気を配ることが重要です。
山口 正寛
1984年生まれ。大阪府出身、東京都在住。データベースエンジニア。SQL Server、Oracle、MySQL、PostgreSQLなどのデータベースで、小規模から大規模な案件まで数多く経験。現在ではクラウドの流れに逆らうことなく、「データベース×クラウド」をキーワードに案件対応、セミナー活動、執筆活動など幅広く活動中。株式会社システムサポート所属。