2017年7月にAzure SQL Data Warehouseの機能がアップデートされました。これまで説明してきた「Data Warehouse ユニット - DWU(第3回)」や「テーブルの分散(第5回)」に関わるアップデートも行われました。今回はこのアップデートのポイントを紹介しますが、いずれの機能もプレビュー版のため、機能の仕様が変更になったり、機能自体がなくなってしまったりする場合があるので、注意が必要です。
Data Warehouseユニットの上限値が6000DWUから18000DWUに
第3回で紹介したData Warehouse ユニット(DWU)。これは、SQL Data Warehouseのパフォーマンスを決定する独自の単位ですが、この上限値が6000DWUから18000DWUへと拡大されました。
9000DWUや18000DWUに設定すれば、事実上、これまでよりもさらにコンピューティング負荷の高い処理を高速に処理できるようになったわけです。しかし、筆者の持つ検証環境で確認したところ、400DWUから9000DWUへアップデートはできないようで、一般提供されるタイミングでどのような仕様になるのか気になります。

|
また、ディストリビューションは従来60でしたが、9000DWUや18000DWUの場合は90や180へ増えるのかどうか、筆者はまだ確認していません。ただし、6000より小さなDWUを指定している場合は、これまでと同様に60のディストリビューションで構成されています。
テーブルの分散方法に新しい分散方法「Replicated Table」が追加
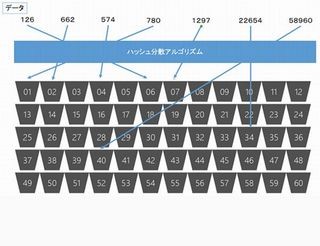
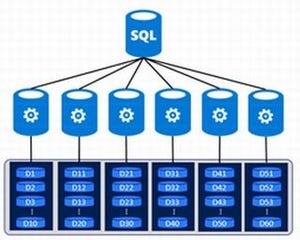
第5回で紹介した内容になりますが、SQL Data Warehouseは複数のストレージ(正確には60のディストリビューション)にテーブル上のデータを分散し配置します。
この分散の方法は基本的に、すべてのテーブルにラウンドロビンにデータを分散し格納していく「Round Robin分散」と、特定カラムをHASH KEYとし、ハッシュ値を計算して配置先のディストリビューションを決定する「ハッシュ分散」の2つしかありませんでした。しかし今回、この分散方式に新しい分散方式が追加されました。それがこの「Replicated Table」です。

|
「Replicated Table」の概要 |
Replicated tableを使用することで、各ディストリビューションに格納されているデータのコピーをすべてのコンピュートノードで持つようになります。これにより、テーブルの結合時などに発生する可能性のある「データ移動」の抑制が可能となりコストが下がります。ただし、以下のように、利用上の制約事項や検討事項もいくつかあります。
テーブルに格納される件数に関係なく2GBの大きさのテーブルまでしか利用できない
INSERTやUPDATE、DELETEなどを行うとレプリケートされている表を再構成する必要があるため、パフォーマンスの低下が発生する場合がある
コンピュートノードを頻繁に変更するような(DWUの数値を頻繁に変更するような)環境の場合も、同様にレプリケートされている表の再構成が行われ、オーバーヘッドが発生する
Replicated Tableを利用する前に、以上のような制約事項や検討事項を把握しておくことは大切です。
ここではReplicated Tableの作り方を紹介したいと思います。
以下のようにCREATE TABLE文のDISTRIBUTION句でREPLICATEを指定すれば、Replicated Tableは作成できます。
CREATE TABLE [dbo].[DimAccount_REPLICATE]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimAccount]
上記の例では、SQL Data Warehouseの中にあるサンプルテーブルのDimAccountを使って、CTASで「DimAccount_REPLICATE」というReplicated Tableを作成しています。
次に、作成したReplicated Table「DimAccount_REPLICATE」の状態を「sys.pdw_replicated_table_cache_state」を使って確認します。
SELECT t.name,c.state
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
上記のコマンドを実行すると、次のようなテーブルが作成されます。
上記のように、作成した直後のReplicated Tableの状態は「NotReady」であることがわかります。Replicated Tableへデータが格納された直後は「NotReady」となり、この状態では各コンピュートノードにコピーは配置されていません。「DimAccount_REPLICATE」テーブルに対してSELECTが実行されたタイミングでコピーが配置されることになります。
SELECT TOP 1 * FROM [dbo].[DimAccount_REPLICATE]
上記のようなコマンドを実行後、Replicated Tableの状態を再度確認してみます。結果、以下のテーブルが作成されます。
状態がReadyとなったことが確認できました。これで各コンピュートノードにコピーが配置されていることになります。
マスターなどのデータ量が少なく、更新の少ないテーブルであれば、Replicate Tableは効果的に動作する分散方式になります。
今回は、7月にSQL Data Warehouseで新しくアップデートされた機能を紹介しました。これらは冒頭でも触れたように2017年8月時点ではいずれもプレビュー版ですが、これまで説明してきた内容に関係するため解説しました。SQL Data Warehouseは日々利用できる機能や性能が進化しており、利用者にとってはうれしい限りです。
山口 正寛
1984年生まれ。大阪府出身、東京都在住。データベースエンジニア。SQL Server、Oracle、MySQL、PostgreSQLなどのデータベースで、小規模から大規模な案件まで数多く経験。現在ではクラウドの流れに逆らうことなく、「データベース×クラウド」をキーワードに案件対応、セミナー活動、執筆活動など幅広く活動中。株式会社システムサポート所属。