連載の5回目でBase64のエンコードと仕組みについて紹介したのですが、その逆のデコード処理はどうやるんだという声がありました。そこで今回はBase64のクレートを比較した後、Base64のデコード処理について解説します。
-
RustでBase64のデコード処理を実装したプログラム

Base64の復習
まずは復習です。Base64とはバイナリデータを、64種類の英数字のみを用いて表現するエンコード方式です。バイナリデータをASCIIテキストとして扱えるので、HTMLファイルやメールに画像を埋め込むなどの用途で利用されています。
なお、本連載の5回目ではBase64の仕組みやエンコード処理について解説しました。
Base64で学べるRustプログラミング
実は、Rust連載の5回目を書いたときに、Base64を実装するのが楽しくなってしまって、手軽に使えるライブラリとして、base64_lightというクレートを作成してcrates.ioに登録していました。
-
RustのBase64パッケージを作ってみた

そもそもcrates.ioというのは、誰でもRustのパッケージを登録して公開できるサイトです。このサイトに登録すると、Rust標準のパッケージマネジャー(ビルドシステム)のcargoコマンドを使って手軽にライブラリをインストールできるようになります。それで、クレート(パッケージ)作成の練習を兼ねて登録してみたのです。
また、時を同じくして、本連載の読者の柳川さまからも、連載の5回目を見てBase64デコードが実装されていないので、デコード処理を作ってみたとメールをいただきました。こちらのブログで紹介してくださっています。
それで、crates.ioでBase64を検索してみると、他にもBase64のパッケージが登録されておりとても参考になります。Base64のさまざまな実装方法を学ぶことができます。プログラムの規模から言っても300行未満で実装できますし、Rustを学ぶのにぴったりの題材です。以下にライブラリの一覧を列挙しましたので、比較してみると良いでしょう。いずれも、リポジトリのsrc/lib.rsを眺めてみると良いでしょう。
RustでBase64を扱うライブラリの一覧:
-
easy_base64 ... Rustらしくとてもシンプルなコードが印象的なBase64ライブラリ
-
rust-base64-compat ... コンパクトで分かりやすいBase64ライブラリ
-
rust-base64-light ... 筆者が作った読みやすさ重視のBase64ライブラリ
- rust-base64 ... 最も使われているBase64ライブラリ
Base64テーブルを準備する方法の違い
なお、Base64の変換処理において変換テーブルをどのように準備するのかという点は、各ライブラリを読み解く上で大きなポイントとなります。
本連載5回目のBase64エンコーダーでは、できるだけプログラムを簡潔で短くするために、文字列でBase64の一覧を記述して、それをVec
// 本連載5回目のプログラムから抜粋
fn base64_encode(in_str: &str) -> String {
// Base64の変換テーブルを1文字ずつに区切る
let t = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
let table: Vec<char> = t.chars().collect::<Vec<char>>();
しかし、これでは実行効率が悪いので、筆者はcrates.ioに登録したクレートbase64_lightでは、最初から定数配列を定義して、これを元にして変換処理を行うように変更しました。
// src/lib.rs より抜粋
const BASE64TABLE: [char; 64] = [
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J',
'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd',
'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x',
'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7',
'8', '9', '+', '/'];
しかし、他のBase64ライブラリのrust-base64を見てみると、&strからas_bytesメソッドを使ってu8の配列に変換するコードがありました。&strからu8への変換は、それほど変換コストもないため、敢えて変換テーブルにするまでもなかったかと気づきがありました。
// src/alphabet.rs より抜粋
const ALPHABET_SIZE: usize = 64;
〜省略〜
const fn from_str_unchecked(alphabet: &str) -> Self {
let mut symbols = [0_u8; ALPHABET_SIZE];
let source_bytes = alphabet.as_bytes();
〜省略〜
pub const STANDARD: Alphabet = Alphabet::from_str_unchecked(
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/",
);
なお、rust-base64は少し複雑なので補足します。Base64では記号の「+/」を「-_」に置き換えたRFC3548というバージョンが存在するのです。そのため、気軽に変換テーブルを差し替えられるように配慮されており、定数STANDARDを指定すると標準のBase64となり、定数URL_SAFEを指定するとRFC3548のテーブルになるという仕組みなのです。これは上手なやり方です。
他にも、別のBase64ライブラリのrust-base64-compatを見ると、次のようにu8の配列で、テーブルを定義していました。
// src/tables.rsより抜粋
pub const STANDARD_ENCODE: &[u8; 64] = &[
65, // input 0 (0x0) => 'A' (0x41)
66, // input 1 (0x1) => 'B' (0x42)
67, // input 2 (0x2) => 'C' (0x43)
68, // input 3 (0x3) => 'D' (0x44)
69, // input 4 (0x4) => 'E' (0x45)
〜省略〜
確かに、最も効率的に処理できるのは、できるだけStringを利用せず、u8の配列(またはスライス)で処理する方法でしょう。
このように、Base64のライブラリを比較してみることで、たくさんの気づきがあります。
Base64のデコード処理を実装しよう
それでは、次にBase64のデコード処理を実装してみましょう。ただし、Base64デコードの処理が分かりやすくなることを一番に考慮しているため、あまり効率的なものではありません。
fn main() {
// Base64文字列をデコードして表示 --- (*1)
println!("{}", base64_decode("aGVsbG8h"));
println!("{}", base64_decode("55Sf5aec54S844GN5a6a6aOf"));
}
// Base64をデコードするための関数 --- (*2)
pub fn base64_decode_bytes(b64str: &str) -> Vec<u8> {
// Base64の変換テーブルを作る --- (*3)
let t = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
let mut table: [u8; 256] = [0; 256]; // 0で初期化
for (i, v) in t.as_bytes().iter().enumerate() {
table[*v as usize] = i as u8; // 文字から数値への変換
}
// 引数に改行コードがあれば削除する --- (*4)
let b64 = String::from(b64str).replace("\r", "").replace("\n", "");
let b64bytes = b64.as_bytes(); // u8の配列に変換
let mut result: Vec<u8> = vec![];
// 24ビットずつ繰り返し変換 --- (*5)
let cnt = b64bytes.len() / 4;
for i in 0..cnt {
// 6ビット×4字分を取り出す --- (*6)
let i0 = b64bytes[i*4+0];
let i1 = b64bytes[i*4+1];
let i2 = b64bytes[i*4+2];
let i3 = b64bytes[i*4+3];
// テーブルで変換する --- (*7)
let c0 = table[i0 as usize] as usize;
let c1 = table[i1 as usize] as usize;
let c2 = table[i2 as usize] as usize;
let c3 = table[i3 as usize] as usize;
// 24ビットにまとめる --- (*8)
let b24 = (c0 << 18) | (c1 << 12) | (c2 << 6) | (c3 << 0);
// 24ビットを3バイトに分割 --- (*9)
let b0 = ((b24 >> 16) & 0xFF) as u8;
let b1 = ((b24 >> 8) & 0xFF) as u8;
let b2 = ((b24 >> 0) & 0xFF) as u8;
result.push(b0);
if i2 as char != '=' { result.push(b1); }
if i3 as char != '=' { result.push(b2); }
}
result
}
pub fn base64_decode(b64str: &str) -> String {
// [u8]をStringに変換 --- (*10)
String::from_utf8(base64_decode_bytes(b64str)).unwrap()
}
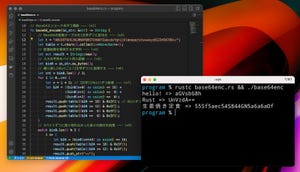
プログラムを実行するには、ターミナルで以下のコマンドを実行します。ここでは、Base64文字列の「aGVsbG8h」と「55Sf5aec54S844GN5a6a6aOf」をデコードして表示します。
$ rustc base64decode.rs
$ ./base64decode
hello!
生姜焼き定食
それでは、プログラムを確認してみましょう。(*1)では、一番最初に実行されるmain関数で関数base64_decodeを実行します。Base64のデータを二つデコードして表示します。