前回に続きNode.jsを使います。今回はNode.jsでプログラムを作成してWebからHTMLデータを読み込んで必要な内容を抜き出します。いわゆるスクレイピングというやつです。

今回はデスクトップのsampleディレクトリにnodejsのプロジェクトを作成します。また、カレントディレクトリはsampleディレクトリとします。コマンドならcd ~/Desktop/sampleです。

プロジェクトを作成する/モジュールを入れる
Webページのデータを読み込むためには最初にプロジェクトを作成します。また、作成したプロジェクトにいくつかのモジュールを入れる必要があります。
最初に以下のようにコマンドを入力します。これで新規にプロジェクトが作成されます。
npm init

プロジェクトに関する情報を入力するように促されます。とりあえず、全てリターンキーを押して進めてください。



次にjsdomを入れます。以下のように入力します。
npm install jsdom

次にrequestを入れます。以下のように入力します。
npm install request


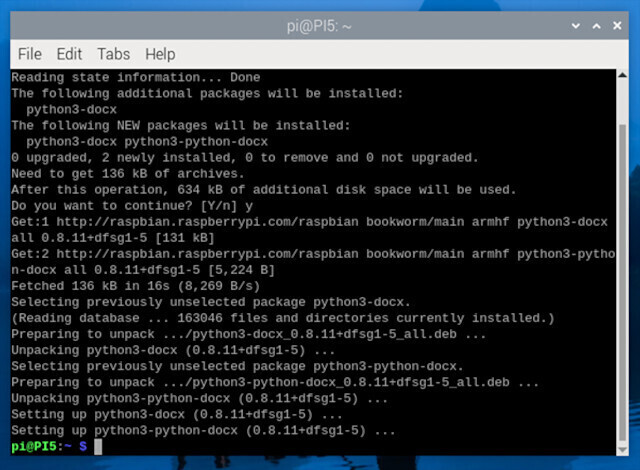
jsdom、requestがインストールされると図のような感じになります。



うまくインストールできなかった、エラーが出る場合は、プロジェクトでディレクトリの作成から再度やってみてください。それでも駄目な場合はNode.jsのバージョンを変えてやってみてください。
この連載の目次のページタイトルを取得する
それでは手始めにこの連載の目次のページタイトルを取得してみましょう。プログラミングの連載なら、ここでプログラムの詳細について説明が始まるのですが、この連載はプログラミングが主ではありませんので詳細な説明はしません。幸にしてNode.jsやJavaScript(ECMA Script)、DOM (Document Object Model) に関する情報はたくさんあります。詳しいことについては各自検索して調べてもらうことにして、ここではプログラムの大まかな処理だけ説明します。
まず、実際のプログラムは以下のようになります。このプログラムをsampleディレクトリの中にindex_title.jsという名前で保存します。
const request = require('request');
const {JSDOM} = require('jsdom');
request('https://news.mynavi.jp/techplus/series/natonakucommand/', (e, response, body) => {
if (e) { console.error(e); }
try {
const dom = new JSDOM(body);
var pageTitle=dom.window.document.title;
console.log(pageTitle);
} catch (e) {
console.error(e);
}
})
このプログラムの最初の2行は、それぞれのモジュールの使用とアクセス用オブジェクトの用意です。
request(〜)の部分でデータを取得したいURLを指定します。ここを変えれば様々なページのデータを取得できます。
const dom = new JSDOM(body);でDOM情報を取得します。以後domという名前のオブジェクト名でページ内のデータにアクセスできるようになります。
var pageTitle=dom.window.document.title;でページタイトルを取得しています。HTMLデータの<title>タグ内のデータにアクセスしていることになります。
console.log(pageTitle);で読み出したページタイトルを標準出力しています。
プログラムの大まかな流れはこんな感じです。それでは実際に実行してみましょう。以下のようにコマンドを入力します。正常に実行されるとページのタイトルが表示されます。
node index_title.js


第1回目の連載のページタイトルを取得する
今度は連載第1回目のページタイトルを取得してみましょう。プログラムは以下のようになります。先ほどのプログラムと異なるのはURLのみです。このプログラムをsampleディレクトリ内に1.jsという名前で保存します。
const request = require('request');
const {JSDOM} = require('jsdom');
request('https://news.mynavi.jp/techplus/article/natonakucommand-1/', (e, response, body) => {
if (e) { console.error(e); }
try {
const dom = new JSDOM(body);
var pageTitle=dom.window.document.title;
console.log(pageTitle);
} catch (e) {
console.error(e);
}
})
保存したら以下のようにコマンドを入力します。正常に実行されるとページのタイトルが表示されます。
node 1.js


第1〜10回目の連載のページタイトルを取得する
次に連載の1〜10回目のページタイトルを連続して取得してみましょう。プログラムは以下のようになります。が、注意点があります。以下のプログラムは非同期で処理されるため、連載の順番通りにページタイトルが返される保証はありません。1回目の後に4回目のページタイトルが出力されたりすることがあります。このプログラムをsampleディレクトリ内にlist1-10.jsという名前で保存します。
const request = require('request')
const {JSDOM} = require('jsdom')
for(let i=1; i<11; i++){
request('https://news.mynavi.jp/techplus/article/natonakucommand-'+i+'/', (e, response, body) => {
if (e) { console.error(e); }
try {
const dom = new JSDOM(body)
var pageTitle =dom.window.document.title;
console.log(pageTitle)
} catch (e) {
console.error(e)
}
})
}
前のプログラムと異なるのは「for(let i=1; i<11; i++){」の部分です。1が取得する最初の連載番号で11が連載番号+1になります。ここの番号を変えれば、好みの範囲の連載記事のページタイトルを取得できます。 以下のようにコマンドを入力すると連載1回目〜10回目までのページのタイトルが表示されます。
node list1-10.js


コマンドラインで連載記事の番号を指定する
次にコマンドラインの引数で連載回数の番号を指定できるようにしてみましょう。プログラムは以下のようになります。このプログラムをsampleディレクトリ内にnum.jsという名前で保存します。
const request = require('request')
const {JSDOM} = require('jsdom')
let num=parseInt(process.argv[2]);
request('https://news.mynavi.jp/techplus/article/natonakucommand-'+num+'/', (e, response, body) => {
if (e) { console.error(e); }
try {
const dom = new JSDOM(body)
var pageTitle =dom.window.document.title;
console.log(pageTitle)
} catch (e) {
console.error(e);
}
})
コマンドラインの引数は「let num=parseInt(process.argv[2]);」で取得できます。「node a.js 12」ならprocess.argv[2]には2が入ります。「node a.js 12 987」ならprocess.argv[2]には12が、process.argv[3]には987が入ります。
以下のようにコマンドを入力すると連載23回目のページタイトルが表示されます。
node num.js 23


コマンドラインで直接URLを指定する
連載記事の番号ではなく、直接URLを指定すれば良いのでは?と思う人もいるでしょう。もちろん可能です。コマンドラインから直接URLを指定できれば汎用性は格段に高まります。実際のプログラムは以下のようになります。先ほどのプログラムと同様にコマンドラインからの引数をそのままrequest(〜)のパラメーターとして指定しています。
const request = require('request')
const {JSDOM} = require('jsdom')
let targetURL=process.argv[2];
request(targetURL, (e, response, body) => {
if (e) { console.error(e); }
try {
const dom = new JSDOM(body)
var pageTitle =dom.window.document.title;
console.log(pageTitle)
} catch (e) {
console.error(e);
}
})
以下のようにコマンドを入力すると連載30回目のページタイトルが表示されます。URLを色々変えてページタイトルが表示されるかやってみてください。
node www.js https://news.mynavi.jp/techplus/article/natonakucommand-30


連載記事の先頭部分の文章を取得する
ここまではページタイトルのみでした。実際のところ、ページタイトルを抜き出しただけでは実用的とは言えません。今度は連載記事の先頭の文章を取得してみます。この連載の先頭の文章はIDがjs-articleBodyの要素(divタグ)内にあります。その中の先頭のpタグが先頭の文章になります。実際のプログラムは以下のようになります。
const request = require('request')