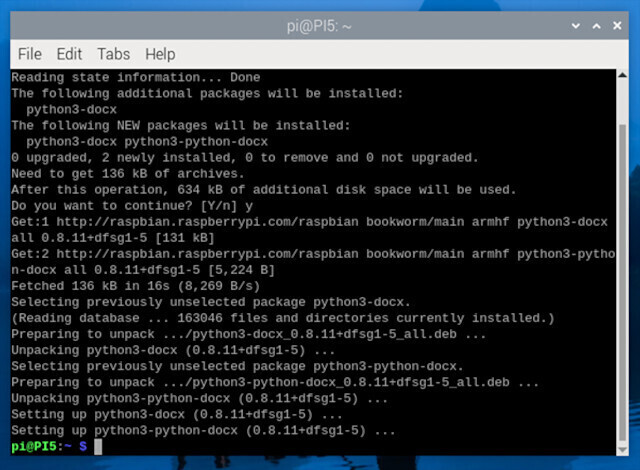
今回はmacOSでマイクロソフト社のエクセルとワードのファイルを扱います。macOSでもマイクロソフト社から正式にmacOS用のオフィスアプリケーションが提供されているので、すでにインストールしている人にとっては今回のネタはあまり意味がないかもしれません。純正のアプリケーションで処理する方が間違いがないからです。
純正のアプリケーションを利用できない環境にある場合や大量にまとめてエクセル・ワード文書の処理を行う必要がある場合は今回説明するコマンドが役立つかもしれません。
今回もこれまでのようにサンプルで利用するファイル・ディレクトリはデスクトップのsampleディレクトリとしています。デスクトップにsampleディレクトリがない場合は作成しておいてください。(コマンド入力ならmkdir ~/Desktop/sampleとして作成することができます)
また、カレントディレクトリも上記の場所になります。cd ~/Desktop/sampleのようにコマンドを入力してカレントディレクトリを変更しておけばよいでしょう。
その名はtextutil
「データはエクセルでください」
「ワード文書で送ってください」
それらのアプリケーションを持っていないと不便ですが、仕事によってはエクセルやワードがいらないため購入しない人もいます。もしくは25年くらい前のエクセルでも十分という人であれば、それをそのまま使った方が安上がりということもあります。(サブスクリプションではないため余計なコストをかけずに済む)
macOSではマイクロソフトオフィスは標準で同梱されていませんが、Apple社が標準でエクセルやワードのデータを閲覧・編集できるアプリケーションを用意してくれています。それらを使えばオフィスがなくても一応内容の確認はできます。
「なんだ、それなら別にいいじゃないですか」
という人もいそうです。はい、その通りです。が、プレーンテキストを素早くワード文書に変換したり、その逆でワード文書をプレーンテキストにするのであればコマンドを使った方が便利かもしれません。特に複数のファイルを手軽に変換する場合には威力を発揮します。
ということで、早速変換するためのコマンドを使ってみましょう。そのコマンドの名前はtextutilです。実はtextutilは以前に使っています。ちなみにターミナルでman textutilとするとマニュアルが表示されます。


プレーンテキストをワード文書に変換する
まず、簡単なところでプレーンテキストをワード文書に変換してみましょう。
カレントディレクトリにある1.txtをワード文書に変換するには以下のように指定します。なお、古いワードのdocも指定できます。
textutil -convert docx 1.txt -output 1.docx


無事に変換が終わると1.docxファイルが生成されます。

マイクロソフトワードがインストールされている場合は生成されたファイルを開くと以下のようになります。

マイクロソフトワードがインストールされていない場合は標準で入っているPagesで開くことができます。

Pagesもない場合はプレビュー.appで開くこともできます。

ワード文書からプレーンテキストに変換する
今度はワード文書からプレーンテキストに変換してみましょう。文書内を検索したい場合には、この方が需要あるかもしれません。この場合は-convertの後に指定する変換形式名をtxtにします。
2.docxをプレーンテキストに変換し2.txtというファイル名で保存するには以下のようにします。
textutil -convert txt 2.docx -output 2.txt

ワードで装飾されている文字の色や書体(フォント)・サイズなどは全てなくなりプレーンなテキストとして変換されています。


HTMLファイルをプレーンテキストにする
今度はHTMLファイルをプレーンテキストに変換してみましょう。この変換に関しては以前の記事でも扱いましたが、細かい説明はなく使っていました。もっとも、あまり細かい説明なく変換できてしまうのが、このコマンドの便利なところです。前回と同じく、本連載の目次ページをダウンロードして処理してみましょう。
https://news.mynavi.jp/techplus/series/natonakucommand/

ここでは一旦カレントディレクトリ内にHTMLファイルをダウンロードしてから処理します。curlコマンドを使ってページデータ(HTML)をダウンロードします。ダウンロード状況を把握するために進捗状況を消す-sは指定していません。特に問題なければすぐにダウンロードは終了します。



ダウンロードしたHTMLファイルをプレーンテキストに変換するには以下のように入力します。
textutil -convert txt index.html -output index.txt




以前の連載でも書きましたが変換する際にエラーが表示されることがあります。このエラーを表示したくない場合は以下のように/dev/nullにリダイレクトします。
textutil -convert txt index.html -output index.txt 2>/dev/null

今度はダウンロードせずにWebデータを読み込込んで処理してみます。curlでデータをダウンロードしてからパイプ(|)を使ってtextutilコマンドに渡します。その際textutilでは標準入力から読み込ませるために-stdinのオプションを指定する必要があります。つまり以下のようにすると指定したURLからダウンロードした内容をプレーンテキストにして保存することができます。
curl -s https://news.mynavi.jp/techplus/series/natonakucommand/ | textutil -convert txt -stdin -output index2.txt



HTMLファイルをワード文書にする
次にHTMLファイルをワード文書に変換してみましょう。先程の変換形式をワード形式のdocxに変更するだけです。
curl -s https://news.mynavi.jp/techplus/series/natonakucommand/ | textutil -convert docx -stdin -output index2.docx