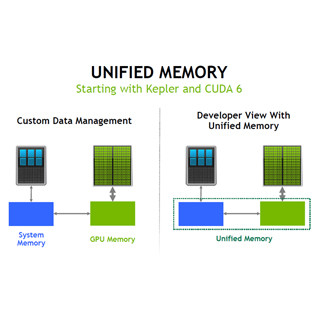
4. プロファイラでカーネルの動作を分析する
NVIDIAはNVVPというプロファイラを提供している。次の図に見られるように、画面の上側は各種の事象のタイムラインで、下側に問題点を解析した結果などを表示する。性能の悪い部分を見つけ出して、改良するためには便利なツールである。

|
|
NVIDIA Visual Profilerの画面表示 |
プロファイラの上側の画面を見ると、Transpose(を行うカーネルが走っている時間)は、かなり少ないことが分かる。そして、Analysisの窓では、どのKernelが一番長い時間が掛かっているかを見つけて、それを最適化すべきという指摘が表示されている。

|
|
プロファイラは実行状況をタイムラインで示し、やるべきことをアナリシスの窓に表示する |
次の図はKernelを最適化の重要性の高い順にならべたもので、doubleのgpuTranspose1_kernelとfloatのgpuTranspose1_kernelがRank 100とRank 99で、重要度が高いことが分かる。
なお、ここには後で出てくるgpuTranspose2以降のカーネルの名前も出てきているので、全部のカーネルを並べたソースプログラムを使っているようであるが、ここではgpuTranspose1以外は気にしなくて良い。

|
|
実行中のカーネルを最適化の重要度(rank)順に並べたリスト |
次にPerform Kernel Analysisをクリックして、Kernelの実行速度が遅い原因を調べる。

|
|
Perform Kernel Analysisをクリックして、Kernelが遅い原因を調べる |
すると、次のリソース利用率のグラフが表示され、その分析が示される。並べ替えだけで演算はない処理であるので、Computeのリソース利用率が低いのは必ずしも問題ではないと思うが、メモリ系も1/3程度のリソースしか利用されていない。この原因は、命令、あるいは、メモリレーテンシの問題であることが多いと指摘されている。

|
|
メモリ系の利用率も低い。命令、あるいはメモリのレーテンシに問題がある可能性が高い |
そして、3のCompute、Bandwidth、or Latencyの項が表示され、命令、あるいはメモリのレーテンシの問題である可能性が高いと指摘されるので、次のPerform Latency Analysisをクリックする。

|
|
命令、あるいは、メモリのレーテンシの問題の可能性が高いと指摘されるので、Perform Latency Analysisをクリックする |
そうするとLatency Analysisの画面が表示され、計算やメモリレーテンシを隠すにはグリッドのサイズが小さすぎるという指摘が出てくる。そして、最適化のためには、Kernelで実行されるブロックの数を増やせと言うアドバイスが示される。

|
|
Kernelが実行するブロック数が少なすぎるのでレーテンシを隠すことができない。ブロック数を増やせと言うアドバイスが表示される |
Gridサイズは(8,1,1)でBlockサイズは(256,1,1)となっており、リソースの占有率は12.5%でしかない。しかし、占有率は理論上100%まで改善することができるという。

|
|
Grid Sizeは(8,1,1)、Block Sizeは(256,1,1)で占有率は12.5%しかない |
メモリコントローラは、いくつかのメモリトランザクションを並列に処理できる。これは管制官が毎分何機を着陸させられるかいうことと同じ意味である。ただし、着陸させる機数を最大にするには、常に着陸待ちの次の飛行機がいなくてはならない。
C5による輸送の例でも分かるように、ボトルネックになる資源(飛行中の機数)は最大の状態を保つ必要がある。離陸が遅れて、空きを作れば性能は低下してしまう。
より多くの並列性は、より多くの同時実行スレッドがあることであり、それによるより多くのロード命令の並列実行と言うことになる。
そしてGPUは並列度を使ってレーテンシを隠すので、リソース占有率を高めることはレーテンシを隠すことに繋がる(仕事がたくさんあれば、飛行機の着陸待ちになっても、別の仕事をやっていれば良い)。

|
|
ボトルネックとなるリソースはフルに利用して性能を上げる。利用率を上げるのは並列度を上げることであり、それによりレーテンシを隠すことができる |