Samsungスマホの核をなすM3プロセサ
Hot Chips 30において、Samsung Electronicsはフラグシップの「Mongoose 3(M3)プロセサ」のアーキテクチャを発表した。このプロセサはSamsungの9810 SoCに組み込まれ、すでにGalaxy S9、Galaxy S9+スマートフォンに使われている。
Hot Chips 30にて発表を行ったのはSamsungのテキサス州オースチンのR&DセンターのJeff Rupley氏である。
M3はSamsungのM1、M2プロセサの後継であるが、段階的な改良ではなく、実行パイプラインなどの幅を広げ、より深く、高速なマイクロアーキテクチャになっている。6命令並列処理と9本の整数系実行パイプライン、3本の浮動小数点系実行パイプラインという構成は、スマートフォン用ではなく、サーバ用CPUかと思わせる重量級の構成である。
-
SamsungのM3プロセサは前世代のM2に比べて実行パイプラインの幅を広げるなど大幅な改良を行ったプロセサである。半導体プロセスはSamsungの10LPPを使い、クロックは2.7GHzである (出典:この連載のすべての図はHot Chips 30でのSamsung SARCのRupley氏の発表スライドのコピーである)

前世代からの改良点
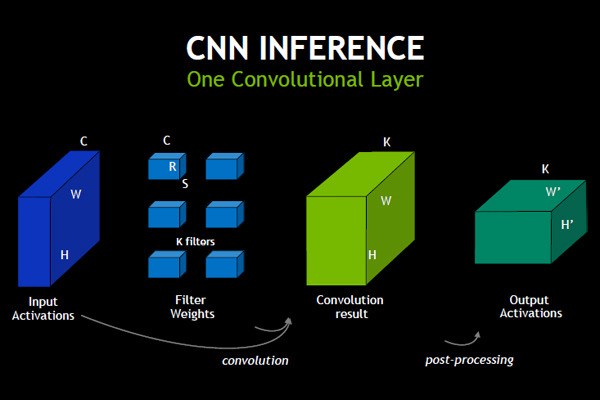
次の図は、M2との比較を示す表とM3プロセサのブロックダイヤを示している。一番大きな改良は、M2では命令処理が4命令並列であったのが、M3では6命令並列に拡張されている点である。また、Out-of-Order実行の結果をIn-Orderに並べ替えてコミットを行うROB(Re-Order Buffer)がM2では100エントリであったものが、M3では228エントリに拡張され、より深いOut-of-Order実行ができるようになった。
ブロックダイヤの基本的な構造はM1、M2と同じであるが、整数系の実行パイプが1本増え、ロードアドレスを計算するパイプラインも1本増えて、2本になった。そして、浮動小数点演算系もFMACのパイプラインが1本増えている。
この構造はサーバ用CPUと比べても引けを取らない。10nmプロセスを使えば、この程度の物量の増加は問題にならないのであろう。ただし、消費電力の増加は問題で、この発表では触れられていないが、そこは各種の省電力技術でカバーしているのであろう。
-
M2は4命令並列処理であったが、M3では6命令並列に拡張された。また、実行パイプラインも整数演算系で1本、ロードアドレス計算で1本、浮動小数点のMAC演算系で1本の計3本が追加された

次の図のグラフはM2とM3プロセサの1000命令あたりの分岐予測ミスの回数(MKPI:Miss Per Kilo Instructions) を比較したものであるが、M2では平均3.92回のミスであったのがM3では3.29回に減少している。これにはBTBなどの容量増加とニューラルネットを使った分岐予測の改善などが効いているものと思われる。
-
M3プロセサのフロントエンド。BTBの容量増加などとニューラルネットを使う分岐予測の採用などで、1000命令当たりの平均の分岐予測ミスをM2での3.92回からM3では3.29回に低減した

実行性能の向上技術
M3プロセサは、1サイクルに6命令デコードで、6μOPをリネーム、ディスパッチ、リタイアができる6命令並列処理アーキテクチャを持ち、最大9個の整数命令を発行できる。また、1サイクルで実行できる命令が増え、一部の命令では0サイクル実行できるようになったものもある。また、整数の除算はM2ではRadix-4で計算しており、商の生成は2bit/cycleであったが、M3ではRadix-16になり4bit/cycleとなっている。
-
命令処理系はM2の4命令から、M3では6命令並列となった。また、実行パイプラインも本数が増えた。また、ROBのエントリ数がM2の100エントリから228エントリに増えた。また、演算のレーテンシも短縮されている

M1とM3の浮動小数点演算命令の実行パイプラインを次の図に示す。M1では2本の実行パイプラインであったものが、M3では3本となっている。また、M1ではFMAC(乗算と累積加算演算)やFAddを実行できるパイプラインは1本しかなく、1命令しか実行できなかったが、M3では3つのFMAC命令、あるいは3つのFAdd命令を並列に処理できるようになった。
その他に暗号化のCrypt命令や型変換のFcvt命令も2命令並列に実行できるようになっており、使用頻度の高い命令については2倍、3倍の実行性能がでる造りとなっている。
また、FMACの演算レーテンシは5サイクルから4サイクルに短縮され、FAddのレーテンシは3サイクルから2サイクルに短縮されている。
-
浮動小数点演算部は実行パイプラインが2本から3本に増強された。特に、FMACやFAddはM2ではサイクル当たり1演算であったが、M3では3演算実行できるようになった。また、演算のレーテンシも短縮されている

(次回は9月25日に掲載します)