本連載では、エンタープライズシステムでコンテナ/Kubernetesを活用した業務システムを開発・運用するエンジニアに向けて、Kubernetesセキュリティの基礎知識、Microsoftが提供するパブリッククラウド「Azure」を使ったクラウドでのKubernetesセキュリティ対策のポイント、注意点などの実践的なノウハウを紹介しています。
今回からは数回にわたり、Kubernetesの監視と監査について説明します。初回となる今回は、Kubernetes の監視のポイントを見ていきます。
クラウド時代の可観測性とガバナンス
クラウド時代の可観測性とガバナンスについて述べる前に、言葉の意味を確認しておきましょう。
システムの内部で何が起こっているのかを外部の情報から把握する能力のことを「可観測性」や「Observability(オブザーバビリティ)」と言います。
「可観測性」はしばしば、従来の「監視」「Monitoring(モニタリング)」とは違うものと強調されることがあります。しかし、違うものというよりは、監視の範囲がリソースとログを中心とした従来よりも広がってきたので、新しく「可観測性」とか「Observability(オブザーバビリティ)」という言葉を使うようになったと理解してよいでしょう。
「可観測性」の対象はKubernetesやセキュリティ関連だけでなく、広範に及びますが、本連載ではKubernetesセキュリティに焦点を当てて説明していきます。
クラウド時代になって変わったこと
可観測性とガバナンスについて、クラウドの時代になって変わったことと変わっていないことがあります。クラウドの時代になり、以前よりも格段に早くシステムを拡張できるようになりました。これは大きく変わった部分です。
サーバやサービスの追加は年に1回あるかないかの作業ではなく、月に数回、単純な拡張であれば1日の作業でも行われます。アプリケーションのリリースが週に何度も行われることは珍しくありません。このような環境下で、個別のリソースを監視して全体を机上でまとめあげることは現実的ではありません。
複数のシステムをまとまりとして監視して掘り下げていくようなアプローチが必要です。新たなリソースを監視対象に加える作業も、自動化されていなければ追い付かなくなってきました。
こうした課題に応えるため、Microsoft Defender for Cloudでは Azure上のリソースをまとめて監視対象にし、セキュリティ推奨事項を列挙してくれます。
また、古い設定や問題のある設定のまま取り残されているリソースを自動的に検出し適宜是正するようなしくみも求められるようになりました。Azure Policy を使うことで自分が構築したポリシーに準拠できているかどうかをチェックし、ポリシーに従わないものを拒否できます。
クラウド時代になっても変わらないこと
一方で変わっていないこともあります。「アラートの頻度が高すぎると人はアラートを無視するようになる」ことは監視についての普遍の真理のようなものです。アラートを受け取って即座に対応しなければならないものなのか、翌朝じっくりと確認すれば良いことなのか区別されなければなりません。
Azure Monitorには、Azureで発生するさまざまな出来事を検知し、アラートをあげて担当者に知らせる仕組みを提供している一方、あとでじっくり確認するためのダッシュボードを作る仕組みも提供しています。
「利用者に近いところから監視を始めて、システムの深いところの監視を作りこんでいく」という、導入の進め方もこれまでと変わりません。
「利用者に近いところから」というのは「利用者目線で動いているかどうか」ということです。ジョブが利用しているCPU使用率が100%になっているとして、果たしてそれは問題なのでしょうか。リソースをしっかり使い切っているというとらえ方ができる場合もあります。
メモリ使用率は何%に達した時にアラートをあげればよいでしょうか。こうした利用者から遠い部分の監視で問題の有無を判断することは難しいですが、5xxエラーが返る決済画面が問題であること(セキュリティの三要素である可用性が損なわれていること)は明確です。
Application Insights を使うことでたとえば決済画面で5xxエラーが繰り返し発生した場合にアラートを発報し、一時的な負荷の上昇によるものなのか、システムにとって攻撃的な異常なリクエストによって発生したものなのかなどを確認できます。
可観測性とガバナンスについて整理できたところで、本連載のテーマであるKubernetesとセキュリティを中心に、クラウド時代に適した可観測性をどのように確保し、ガバナンスを行えるかを説明していきます。
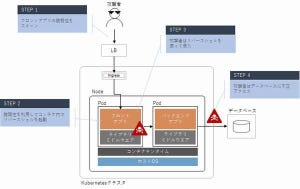
カバー範囲の広いKubernetesの監視
これまでの内容から、Kubernetes は多くのコンポーネントで構成されていることを理解いただけたと思います。これは、監視や監査をそれぞれのコンポーネントに対して行わなければならないことを意味します。
また、Kubernetesを利用する多くの場合、Kubernetesのコンポーネントだけでなくコンテナレジストリやロードバランサーなどの関連する機能やサービスが必要になるため、それらに対しても監視が必要です。
つまり、Kubernetes だけでなく、システム全体としてどのような監視や監査が必要であり、必要な情報をどのような方法で取得するかを検討したうえで実装していく必要があります。クラウドプラットフォームで提供されているマネージドのKubernetesを利用する場合、プラットフォームの機能を利用できることがあるため、併せて検討します。ここではまず、Kubernetesの監視や監査をする際のポイントを整理していきましょう。
Kubernetes Hardening Guidance では、管理者による監視対象のポイントとして以下が挙げられています。
- API リクエストの履歴
- パフォーマンスのメトリクス
- デプロイメント
- リソース消費量
- システムコールの操作
- プロトコルやパーミッションの変更
- ネットワークトラフィック
- Pod のスケーリング
- ボリュームマウント
- イメージやコンテナの変更
- 特権の変更
- スケジュールジョブの作成と変更
サーバやアプリケーションの監視や監査というと、アプリケーションや OS のログ、CPU 使用率・メモリ使用量のようなメトリックが浮かぶのではないでしょうか。しかし、さまざまなコンポーネントやOSの機能で実現されているKubernetesはそれ以外にも多くの監視・監査できる仕組みがあります。