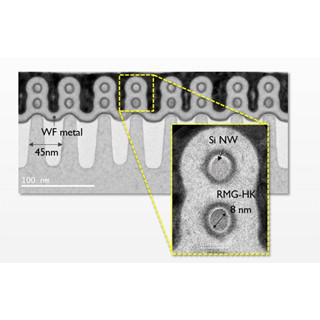
先端ロジック各社の微細化を検証
それでは、各社の微細化の程度をどうやって比較すればよいか。
世界最大のリソグラフィ装置メーカーであるオランダASMLは、独自に微細化の指標となる技術ノードを「標準ノード」と称して、次のように定義している。
標準ノード=0.14×(CPHP×MMHP)0.67
ここでのCPHPはContacted Poly Half Pitch(コンタクトホールのあるpoly-Si配線のピッチの1/2の長さ)、MMHPはMinimum Metal Half Pitch(最小線幅のメタル配線のピッチの1/2の長さ)を表す。
IC Knowledgeが収集してきた先端各社のデータをこの定義に当てはめて計算した結果が表1となる。この表から明らかなように、Intelの標準ノード(CPHPとMMHPの微細化)は22nmまでは競合他社より甘いものだったが、競合企業がこの事実を自社技術の優位性の宣伝に使ったため、Intelは14nmからは他社より厳しい微細化に取り組んでいる。このため、Intel社内で14nm MPUの歩留まり向上が困難を極め、低歩留まりに長期間悩まされ、最新世代のMPUの発売が大幅に遅れてしまった。今後もこの傾向は続き、他社に(見掛け上の)技術ノード競争で数年の遅れをとることになるだろう。しかし、新興ファウンドリでもあるIntelは、むしろトランジスタ性能や集積密度で勝負をかけるつもりだろう。

|
|
表1 先進4半導体メーカー(ファウンドリ含む)各社の"商用ロジックノード"と"標準ノード"との対応。最左行:半導体企業名、最上段:各社の商用ロジックノード、表中の数値:標準のード(予測される生産開始年) (出所:IC Knowledge) |
一方、TSMCとSamsungの標準ノードは10nm以降は同一であり、両社は、AppleからのiPhone用プロセッサの大量注文がかかっているので、熾烈な微細化競争をくりひろげている。Intelの参戦もあり、うかうかしてはいられない。
TSMCの製造コストは20nmと16nmで逆転
各社独自のロジック技術ロードマップの一例として、TSMCの28nmから3.5nmに至るロードマップを表2に示す。赤字部分はIC Knowledgeの予測である。3.5nmでは、FinFETの代わりに3次元積層横型ナノワイヤを採用して集積密度を向上させるとIC Knowkedgeは予測している。
TSMCの20nmノードと16nmノードのCPP(Contacted Poly Pitch:コンタクトホールのあるpoly-Si配線のピッチの長さ)とMMP(Minimum metal Pitch:メタル配線層のうちで最小寸法のピッチの長さ)は同一であるから、20nmと16nmの標準ノードは、表1に示されているようにともに18であり、微細化に関して技術的進歩がないように見える。しかし、表2からもわかるようにCPPやMMP以外のところで改善がみられ、結果としてトランジスタ特性や集積密度が向上している。
IC Knowledgeが独自に行った製造コスト分析によると、TSMCの130nmから5nmに至るウェハ当たりの製造コストはうなぎのぼりに上昇しているが、逆に微細化による配線幅やトランジスタ面積は著しく縮小してきており、結果としてチップ当たりのコストは、微細化の進化とともに着実に低減している。これこそが微細化を進めるモチベーションである。ただ1つの例外は、上述した20nmと16nmプロスで、標準ノードが同一(つまり配線寸法が同じなので配線密度も同一)だったため、チップ当たりの製造コストは20nmより16nmの方がやや高くなってしまっているとIC Knowledgeはコスト分析している。

|
|
表2 TSMCのロジックデバイスのロードマップ (出所:IC Knowledge)。最左欄は上から, 商用ロジックノード、西暦(年)、トランジスタの構造、トランジスタのチャネル材料(N型MOS/P型MOS)、しきい値電圧、金属配線層数、コンタクトおよびヴィア材料-インターコネクト材料、歪みを生じさせるための材料、コンタクトのあるpoly-Si配線ピッチ幅(nm)、最小線幅の金属配線層のピッチ幅(nm) (略語は、HNW=Horizontal Nano Wire(横型ナノワイヤ)、DSL=Dual Stress Liner、SM=Stress Memorization、eSiGe=embedded Silicon Germanium) |