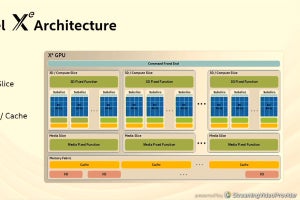
TPU v2/v3の性能
TPU v1の論文ではGoogleがデータセンタで運用する6種の実アプリケーションの実行性能が示された。この論文では各アプリケーションの詳細は公表されなかったが、今回は、その内の4アプリケーションについて基になる論文が示された。
-
TPU v1の論文でも使われた6種のGoogleの実アプリ。今回、出典が明らかにされた

これらの実アプリを最新のTPU v3で実行した場合の性能を示すのが次のグラフである。MLP0アプリをTPU v3で実行した場合のスケーリングの状態を紫の折れ線グラフ、MLP1アプリのスケーリングを緑の折れ線で示す。MLP0では1024チップのTPU v3システムで動かした場合の性能は理想的な1024倍の約40%、MLP1では約14%となっている。ただし、この性能の飽和はEmbeddings(あるデータをより次元の小さい空間に落とし込む操作)によって起こっているという。
-
TPU v1の論文の2つのアプリを1024チップのTPU v3で実行した場合の性能向上。MLP0では約400倍、MLP1では140倍程度

次の図は6種の実アプリをTPU v3スパコンで実行させた場合のスケーリングを示すもので、MLP0とMLP1の結果は、前の図に示したようにあまり良いスケーリングではなかったが、CNN0の場合は完全スケーリングの96%の性能が得られた。また、CNN1、RNN0、RNN1では、理想の99%とほぼ理想的な性能アップが得られた。
-
前の図の2つのアプリのスケーリングは理想的ではなかったが、CNN0では理想の96%、CNN1、RNN0、RNN1では理想の99%のスケーリングが得られた

MLP0を改善したのがMLP0-nextである。MLP0-nextは新しい、より大きなモデルであり、品質を改善するため、ソフトウェアの改良を行なったモデルである。これらの改良により、MLP0-nextでは理想の67%のスケーリングが得られるようになった。
-
MLP0では1024チップのTPU v3でも理想の40%の性能スケーリングであったが、プログラムを改良したMLP0-nextでは理想の67%までスケーリングが向上した

TPU v2 とv3の比較では、ピーク計算性能では2.7倍、クロック周波数とメモリバンド幅では1.3倍となっている。これに対してMLPerf 0.6ベンチマークの5種のモデルでは、幾何平均で1.82倍の性能が得られた。また、Googleが実運用に使っている6種のモデルでは、幾何平均で1.78倍の性能となった。
両者は、幾何平均では比較的近い1.8倍程度の性能向上となったが、それぞれのアプリケーションでは1.4倍から2.3倍までばらついており、なにがどう効いているのかは良く分からない。
-
TPU v2とv3をハードウェアの素性能とMLPerf0.6の5種のベンチマークの性能、Googleの6種のアプリケーションの性能を比較したグラフ。MLPerfは幾何平均で1.82倍、Googleアプリの幾何平均は1.78倍と似通った結果であるが、中身はばらついている

次の図の2018年11月のMLPerf 0.5と2019年5月の0.6との比較では、同じTPU v3での結果であるが、MLPerf 0.6の方が1.4倍~3.5倍の性能で、メディアンでは2.1倍の性能となっている。
また、棒グラフには入っていないが、CNN0では1.8倍に性能が向上しているが、これはbfloat16の使用が性能を高めているようであるという。また、MLP0も1.6倍に性能が向上したが分割のやり方やエンベッディングの改良が効果を上げていると考えられるという。
-
MLPerf 0.5と0.6の性能比較。MLPerf 0.6の方が中央値(Median)では2.1倍の性能となっている。このグラフには無いが、GoogleのCNN0では1.8倍、MLP0では1.6倍の性能が得られている

次の図はLSTM0の推論の性能の改善を示すもので、TPU v1では1回の推論に120ms近くかかり、 50推論/秒程度の性能であったが、TPU v2では、推論時間は40msに短縮され、毎秒270推論が実行できるようになった。
そして、推論のスループットが上がったので、複数の入力をまとめてバッチサイズ大きくして実行することにより、推論時間は60msと長くなったが、530推論/秒までスループットが向上した。
そして、TPU v3で大きなバッチサイズで実行した場合は、推論の実行時間は45ms程度で、スループットはTPU v2と同じ530推論/秒の性能となった。
-
TPU v1、v2、v3での推論性能の比較。V1では1つの推論に120ms掛かり、毎秒40推論程度であったが、TPU v2では40ms/推論程度で毎秒270推論を実行できるようにあった。推論時間が短くなったので、多くの推論をバッチとしてまとめて実行しても応答時間を守れるようになった。そして、バッチを大きくすることで、スループットが530推論/秒まで向上した

TPU v2とv3スパコンは256-1024チップで大規模な実運用アプリケーションを実行している。また、TPUは運用と研究の両方の場面でマシンラーニングの実行を加速している。
そして、この成果が示すように、モデルとハードウェアとソフトウェアのコデザインは、今後もより広い場面で成果を上げると考えられる。
-
TPUv2、v3スパコンは実アプリの実行や研究に広く使われている。モデル、ハードウェア、ソフトウェアのコデザインにより、まだ改善の余地はある