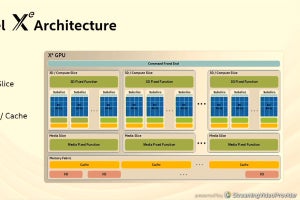
TPUコアはベクタユニットと128×128の行列乗算器を持つ
TPUコアはベクタユニットに加えて、128×128要素のシストリックアレイ方式の演算器を備えている。左手側(Left Hand Side)の入力データと演算結果はストリームで供給、取り出しを行い、右手側(Right Hand Side)のデータは固定である。
そして、TPU v2はこのシストリックアレイの演算に、符号が1bit、Exponentが8bit、Mantissaが7bitで全長16bitのBfloatという数値表現を使った。現在では多くのアクセラレータがbfloatを使っているが、GoogleがTPU v2に採用したのが始めである。なお、積の計算にはbfloatを使っているが、多数の積の和を取る部分ではより高い精度が必要であり、float32が使われている。
-
マトリクス乗算ユニットは128×128要素のシストリックアレイ構造である。この乗算には16bitのbfloat16形式の数値を用いてハードウェアを簡素化している

TPU v1では256×256のマトリクス乗算器が用いられたが、なぜ、TPU v2では128×128のマトリクス乗算器になったのか? 次の図のグラフは256×256、128×128、64×64の3種の演算器を使う場合のオペランドが何回利用できるか(赤)とデータの有効使用率(青)を示している。
なお、この図では256×256の場合は演算器の個数は1個、128×128の場合は4個、64×64の場合は16個として、総演算量は変わらない条件で比較している。
シストリックアレイのサイズを小さくするとムダなデータ読み込みは減り、有効利用率は上がるが、128×128から64×64にしても改善は小さい。一方、オペランドの使用回数は64×64では128×128の半分に減ってしまう。
これらを考えると、サイズは128×128とするのが良い。
-
読み込まれたオペランドが何回使用されるか(赤)とオペランドの利用率(青)を示す折れ線グラフ。このグラフから見て128×128が効率が良い

TPU v2では色々なマトリクス処理が行われるので、効率的な処理のために、転置、簡約化、置換を行うユニットを付け加える。
-
汎用的なマトリクス変換のために、転置、簡約化、置換を行うユニットを設ける。このユニットは、通常、ベクタレーン間のデータの入れ替えも行える

TPU v2ではメモリは高バンド幅のHBMを使用
メモリシステムのロード、ストアはSRAMのスクラッチパッドに対して実行するようにして、予期せぬ待ち時間が発生せず一定時間で実行でき、スケジュールが狂わないようになっている。
そして、HBMは複数のベクトルをストライド的にアクセスでき、メモリバンド幅が大きい。また、HBMは非同期のDMAアクセスができ、 Sync FlagでDMAの終了を通知できるようになっている。
-
HBMロード、ストアはスクラッチパッドメモリに対して行い、一定時間で実行できるようになっており、スケジュールが狂うことは無い。TPUには高バンド幅のHBMが接続されており、非同期のDMAでアクセスすることができる。そして、DMAの終了はSync flagで通知される

TPU v2システムは2次元のトーラスネットワークで接続され、インタコネクトルータは4つのリンクポートを持っている。各ポートのバンド幅は500Gbit/sである。このインタコネクトは、ソフトウェア的にはDMAと同様にアクセスでき、通信先のTPU v2のチップIDを指定してDMAを行えば、データが送られるようになっている。
-
キャプションがここに入ります

TPU v2チップのフロアプランは、次の図のようになっており、共有されるインタコネクトルータがチップの中心に置かれ、チップの上半分に1つのコア、下半分にもう1つのコアが置かれている。
-
TPU v2チップのフロアプラン。インタコネクトルータがチップ中央に置かれ、ほぼ回転対称2つのコアが配置されている。水色の演算系のリソースの面積が大きいが、緑のHBMとデータパスも大きな面積を占めている

演算器を倍増したTPU v3
TPU v3ではマトリクス乗算ユニットを倍増している。それに加えて、演算を行うコアのクロック周波数が30%アップになっている。したがって、TPU v2に比べてv3のピーク演算性能は2.6倍に向上している。この性能の向上を支えるため、HBMのメモリ容量は倍増し、メモリバンド幅は30%アップとなっている。さらに、インタコネクトルータのバンド幅も30%増しとなっている。
そして、より大規模の問題を解くため、システムとして接続できる最大ノード数が4倍の1024チップに拡張されている。
-
TPU v3では、TPU v2と比較してマトリクス乗算ユニットが2倍搭載されている。そして、黄色の札が貼ってあるように、演算器のクロックやHBMのメモリバンド幅などが30%アップとなっている

(次回は9月10日に掲載します)