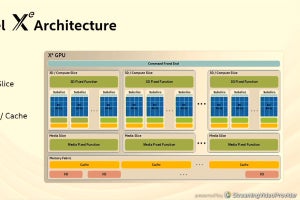
Googleは他社に先駆けてマシンラーニングの推論用のアクセラレータである「TPU」を開発した。初代のTPUについては論文発表も行われたので、その造りはある程度分かっていた。その後、Googleはこれに続いてTPU v2、TPU v3を開発し自社のデータセンタに設置して使用していることが報じられたが、TPU v2やv3ついては学会発表は無く、その詳細は不明なままであった。
しかし、Googleは2020年8月にバーチャル開催されたHot Chips 32において、「Google's Training Chips Revealed: TPU v2 and TPU v3」と題する発表を行い、その内容を明らかにした。
TPU v2/v3は学習を行うアクセラレータ
TPU v1は推論専用のアクセラレータであるが、v2およびv3は学習も行える設計になっている。
学習を行うため、偏微分を行って勾配を求めたり、誤差を出力側から入力側に逆伝搬して重みの値をチューニングする必要があり、推論専用と比べて多くの計算が必要となる。また、この逆伝搬のデータを記憶しておくためにメモリも多く必要になる。さらに、v1のような8ビット整数では表現できる数値範囲や精度が低いので、学習のためには数値の幅を広げることが必要になる。
そして、実験や最適化を行うためには、マシンラーニングのいろいろな処理方法をプログラムできる必要がある。さらに、学習の場合は複雑な大きな問題を速く解くScale-upが要求される。推論の場合はハードウェアを並べて並列度を増やせば済むScale-outで良かったが、規模の大きな問題を短時間で解くScale-upにはいろいろと難しいチャレンジが出てくる。
-
TPU v1は推論専用アクセラレータであったが、v2、v3では学習をアクセラレートすることが必要になり、計算量が増えるし、もっと多くのメモリが必要。計算精度も上げる必要があるなどのチャレンジが出てくる (この連載のすべての図は、Hot Chips 32におけるGoogleの発表資料をビデオキャプチャしたものである)

要求される事項は次のようなもので、短期間での開発、そして高い性能を実現することが求められ、そこに、大規模になっても性能が発揮できる、解く問題は初めて出会うものでどういう構造がよいかが分からないが、コストは安くなどの要求が付け加わる。
-
さらに、開発期間は短く、性能は高く、それでも大規模までスケールする設計で、コストも安く。加えて、解く問題は性質の分からない新しい問題という困難が付きまとう

次の図は、TPU v1を発表した時のもので、ニューラルネットの入力のアクティベーションを中央のストレージから読み出し、それを行列乗算ユニットでDDR3メモリから読み出された重みと掛け合わせ、これらの積項をアキュムレータで足し合わせ、アクティベーションパイプラインを通して、次のニューロン層の入力としてアクティベーションストレージに書き戻す。TPU v1は、このループをできるだけ速く回すことを狙って開発された。
-
TPU v1はアクティベーションストレージから入力データを読み出し、行列乗算器でDDR3メモリから読んだ重みと掛け合わせる。そして、アキュムレータで合計を求めて、次のニューロン層の入力としてアクティベーションストレージに格納するというループを高速で回す

TPU v1をベースに学習用のコアを作る
このTPU v1のブロックダイアグラムをベースにして、まず、アキュムレータとアクティベーションパイプラインのブロックの位置を入れ替える。これはマトリクス演算のブロックとアクティベーションパイプラインという緑色の計算中心のブロックを隣接させるためである。
-
アキュムレータとアクティベーションパイプラインのブロックの位置を入れ替え、右側に緑色の計算ブロックを集める

その次は、推論を行うだけのv1ではDDR3メモリの内容(重み)を書き換える必要はないが、学習を行うv2ではDDR3メモリのデータを書き換えるので、DDR3の位置を変更する。そして、学習では、演算などの操作がもっと多く必要になるので、アクティベーショストレージやアクティベーションパイプラインを汎用のベクタメモリとベクタユニットに交換する。
-
学習のために汎用のベクタメモリとベクタユニットに入れ替える。そして、書き換えの多いDDR3メモリをベクタメモリに直結する

そして、DDR3ではメモリバンド幅が不足であるので、高バンド幅のHBMメモリに変更する。
-
DDR3メモリではバンド幅が不足であるので、HBMに交換する

(次回は9月8日に掲載します)