HSAの仮想命令セットHSAIL
HSAILは、HSAシステムに組み込まれるすべてのGPU、DSPなどのHSAコンポーネントに共通の仮想的な命令セットを定義している。
OpenCLで記述されたプログラムはEDGやClangなどのフロントエンドでOpen CLのSPIR(Standard Portable Intermediate Representation)に変換され、LLVMで最適化を行ってHSAILに変換する。そして、バイナリ形式のHSAILコードを実機に持って行き、Fanalizerと呼ぶツールで実ハードウェアの機械命令に変換して実行する。

|
|
HSAILはHSAによる並列処理のための中間言語である |
HSAILは、並列性があり、共通の仮想メモリ空間をサポートし、HSA Foundationメンバーの装置の間でポータビリティーがあり、製品の世代が変わってもそのまま使い続けられるという設計になっている。また、数値計算の精度の保証があり、どのメーカーのハードウェアを使っても矛盾のない計算結果が得られる。
そして、Finalizeプロセスは高速で安定しており、ハードウェア命令を書かなくても、高性能が得られるというのがHSAILの主要な特徴である。

|
|
HSAILの主要な特徴 |
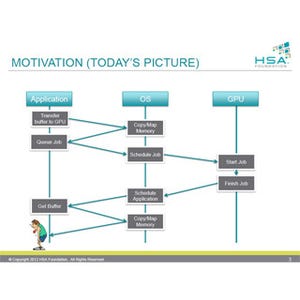
HSAの並列実行モデルは次の図のようになっている。

|
|
HSAの並列実行モデル |
ワークグループという3次元の仕事の集まりがあり、その中の1つ1つがワークアイテムで、これが1つのスレッドで処理される。スレッドはWavefrontと呼ばれる単位で並列に実行されるが、その数はハードウェア依存である。
そして、ワークグループが3次元に配列されたグリッドがHSAでの処理対象となる。
このモデルはOpenCLやNVIDIAのCUDAとほぼ同じである。 HSAILの命令セットであるが、RISC CPUのアセンブラ記述と似ており、命令コードとオペランドとなるレジスタや数値を記述する。

|
|
HSAILの命令セットの概要 |
定義されている命令数は136で、演算命令で扱えるデータは64/32/16ビットの浮動小数点数と64/32ビットの整数である。このほかに、パック形式のデータが扱える命令がいくつかある。
そして分岐命令、Atomicなメモリアクセスを行う演算命令がある。Atomic命令はCPUとHSAコンポーネント間の実行の同期を取るために用いられる。
HSAILのコードはアセンブラのようなテキストで表現する方法と、BRIGと呼ぶバイナリ形式で表現する方法がある。
HSAILでは、メモリ空間には、Global、Readonly、Group、Spill、Private、Arg、Kernargという7種のセグメントが定義されており、メモリをアクセスする命令は、どのセグメントへのアクセスであるかを指定することができる。

|

|
|
HSAILのセグメントとメモリ |
|
Globalセグメントは、CPUも含めて、HSAのすべてのコンポーネントがアクセスできるセグメントである。
Groupセグメントはワークグループ内で共有されるメモリセグメントで、通常、高速のローカルメモリが割り当てられる。
Spill、Private、Argセグメントはワークアイテムを処理するスレッドごとに取られるスタック領域で、通常は、プログラマは意識する必要はない。Spill、Private、Argの区別は、コンパイラがデータをどのように使うのかを示しており、レジスタのあふれを記憶するSpillの場合は、近い将来に読み込まれる可能性が高いのでL1キャッシュに割り当てるというヒントになる。
Kernargセグメントは、カーネルに引数などを渡すために使われ、Readonlyセグメントは、実行中に値が変わらないデータを格納するために使われる。
このように用途の異なる7種のセグメントがあり、ワークグループごと、ワークアイテムごとなどの対応が異なる。これを図示したものが次のスライドである。
なお、すべてのセグメントはグローバルのフラットな仮想空間にマップされており、セグメントを指定しないメモリアクセスは単一のフラットな仮想空間のアクセスとなることが大きな特徴である。

|
|
Grid、Work-Group、Work-Itemと各種セグメントの関係。また、すべてのセグメントはフラットアドレス空間にマップされている |
つまり、セグメントは使われ方のヒントであり、そのセグメントをローカルメモリやキャッシュ、テクスチャキャッシュなどに割り当てるヒントになるが、どのセグメントのデータでもフラットアクセスを使えばアクセスできるようになっている。
HSAILでは、1ビットのコントロールレジスタと、32ビット、64ビット、128ビットのレジスタが使える。コントロールレジスタの数は8個で、その他のレジスタは32ビットレジスタ換算で128個で、64ビットレジスタなら64個、128ビットレジスタなら32個となり、サイズの異なるレジスタが混在してもよい。
SPIRはレジスタ数は無制限であり、LLVMでレジスタカラーリングを行ってこのHSAILのレジスタへの割り当てを行う。従って、Finalizerのところでは、手間のかかるレジスタ割り当てを行う必要はない。

|
|
HSAILのレジスタ |
HSALの実行モデルはSIMT(Single Instruction Multiple Thread)である。この実行モデルはNVIDIAのGPUやAMDのGCNアーキテクチャのGPUの実行モデルと一致している。

|
|
HSAILの実行モデルはSIMT |
HSAにはBaseとFullという2つの準拠プロファイルが定義されている。Baseプロファイルでは、64ビットの倍精度の浮動小数点演算はサポートされず、丸めモードも1種だけでデノーマル数もサポートされない。また、割り算や平方根の計算精度も低くなっている。しかし、Baseモードでも精度が規定されているので、メーカーごと、製品ごとに計算結果が異なるということはない。

|
|
HSAのBaseとFullプロファイル |