Turingのメモリ階層
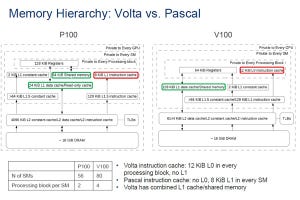
次の図にT4 GPUとP100 GPUのメモリ階層を示す。P100では命令キャッシュはL1命令→L1.5命令→L2共通という階層であったが、T4ではL0命令→L1.5命令→L2共通という階層に変わった。L1がL0と名前が変わっただけではなく、P100のL1命令キャッシュはSMごとに1個置かれていたが、T4のL0命令キャッシュはProcessing Block(Turing SMの1/4)ごとに設けられ、他のProcessing Blockの命令フェッチと競合することも無いし、アクセス時間も短くできる。
そして、T4ではL1データキャッシュとシェアードメモリが一体の構造になった。両方のアクセスが同じデータパスを使うので性能が低下するようにも見えるが、メモリ全体のバンド幅が広がり、アクセスも高速になっているので、性能が上がっている。また、L1データキャッシュとシェアードメモリの配分を変えることができ、柔軟性が増している。
また、L1データキャッシュの入れ替えポリシーが変更され、大きなアレイがキャッシュに残りやすくなったという。
-
P100ではSMごとであったL1命令キャッシュがT4ではProcessing Block単位のL0命令キャッシュになりアクセスが速くなった。また、L1データキャッシュとシェアードメモリが一体化された。これにより、メモリバンド幅が拡大され、アクセス時間も短縮された

さらに、Citadelのチームは、マイクロベンチマークでTuringとVoltaにスケジューラと独立なL0命令キャッシュがあることを見つけた。Kepler以降のNVIDIA GPUの命令キャッシュの階層と容量を次の表に示す。
また、すべてのGPUアーキテクチャでL1命令キャッシュはSMレベルに存在し、L2キャッシュは全SMに共通に存在することを見つけた。
-
上の表は各GPUアーキテクチャでの命令キャッシュの階層と容量。すべてのGPUでL1命令キャッシュはSMレベルに存在し、L2キャッシュは全SMに共通な存在となっている

レジスタファイルのポートの再設計
TuringとVoltsではレジスタファイルの設計は同じで、2バンクでそれぞれ32bitのポートを2つ持っている。一方、Pascal、Maxwell、Keplerでは4バンクのシングルポートのレジスタファイルで作られている。
Turingの場合、偶数レジスタはバンク0、奇数レジスタはバンク1に割り当てられので、FFMA R6,R97,R99,RXとすると、R97とR99は同一バンクになる。そして、RXも同一バンクとなると3つの読み出しポートが必要となり、コンフリクトが生じて1サイクルではアクセスできないことになる。一方、命令がFFMA R6,R98,R99,RXの場合は、R98とR99はバンクが異なるので、RXがどちらのバンクになってもレジスタファイルからの読み出しは最大2つで、コンフリクトは生じない。
次の図のグラフは、この両者のレジスタ割り付けでの実行時間を測定したもので、後者のレジスタ割り付けの場合は6.6~6.7μsで一定であるが、前者の割り付けではRXが奇数の場合はコンフリクトが生じて実行時間が8.3μs程度に伸びている。
なお、T4のコアクロックは1350MHzで、この実行時間の増加は2.3サイクル程度に相当する。1サイクルの増加でできてもよさそうであるが、なぜ、これだけ実行時間が伸びるのかについてCitadelの考察は書かれていない。
-
Turingは2ポートのレジスタファイルが2バンクの構成。FFMAで3つの入力オペランドが同一バンクになると一時には読めない。この場合、実行レーテンシが6.6~6.7μsから8.3μsに増加する

演算器性能
Pascalでは整数と単精度命令のレーテンシが6サイクルであったが、TuringとVoltaではこれらが4サイクルに短縮されている。
一方、倍精度のDADD、DMUL、DFMAはPascal、Voltaでは8サイクルであったが、TuringではDADD、DMULは~48サイクル、DFMAは~56サイクルと格段に遅くなっている。これはTuringは倍精度演算を使う一般的な科学技術計算をターゲットにしておらず、32bitの単精度浮動小数点演算で済むグラフィックスやAI分野をターゲットにしていることを意味している。
-
Pascal、VoltaとTuringの命令実行レーテンシ。Pascalでは6サイクルであった整数と単精度の演算がTuringとVoltaでは4サイクルに短縮されている。一方、Turingでは倍精度の浮動小数演算のレーテンシは非常に長くなっている

シェアードメモリのレーテンシ
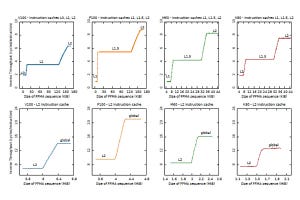
次の図は各GPUのシェアードメモリのアクセスレーテンシを示すグラフである。横軸は同じバンクの異なるアドレスをアクセスするスレッド数で、右側に行くにしたがってバンクコンフリクトの数が増えていっている。そのため、アクセスレーテンシが増えていっている。
このグラフに見られるように、シェアードメモリのアクセスはVoltaが最も速く、Turingはそれに次ぐ。
-
シェアードメモリのアクセスレーテンシ。横軸は同じバンクをアクセスするスレッド数で、これが増えると、バンクコンフリクトが増え、アクセスレーテンシが遅くなる

TLBのカバレージ
次の図はTLBのカバーする容量を測定した結果である。T4、V100のどちらも32MiBまでの領域、32MiBから8192MiBの領域、8192MiB以上の領域でメモリアクセスのレーテンシが分かれている。
32MiB以下のアレイはL1 TLBのミスなくアクセスできるのでメモリアクセスは最も高速である。アレイが32MiBを超えるとL1 TLBのミスが発生し、その分、アクセスレーテンシが大きくなる。そして、アレイが8192MiBを超えるとL2 TLBのミスが発生してアドレス変換に時間がかかり、レーテンシ延びている。
L1 TLBのエントリは2MiBで16エントリあり、32MiBをカバーし、L2 TLBは32MiBエントリで256エントリで8192MiBをカバーしている。
-
T4、VoltaともにL1 TLBは2MiBエントリで32MiBをカバーする。L2 TLBは32MiBエントリで8192MiBをカバーする

Pascal GPUではL1 TLBは2MiBエントリで32MiBをカバーし、L2 TLBは32MiBエントリで2048MiBをカバーする。その前のKeplerとMaxwellは3レベルのTLB階層で、L1 TLBは128KiBエントリで2MiBをカバーし、L2 TLBは2MiBエントリで128MiBをカバーし、L3 TLBは2MiBエントリで2048MiBをカバーしていた。
TLBのエントリが大きいと、使わない部分までメモリを獲得してしまうという無駄が出る。一方、エントリが小さいと一定のメモリをカバーするのにたくさんのエントリ数が必要になってしまう。TLBのエントリサイズとエントリ数は、このあたりのバランスで決められるが、全般にメモリ量が大きくなるとエントリのサイズは大きくなっていく。このため、Pascalまでは最終TLBのカバー範囲は2048MiBであったが、Volta、Turingでは8192MiBのカバレージになった。
-
Kepler、MaxwellからPascalまでは最終TLBのカバー範囲は2048MiBであったが、Volta、Turingでは8192MiBにカバー範囲が増えている

細粒度ポインタ追跡法で調査対象の全GPUのL1データキャッシュのレーテンシを測定した。その結果、T4とV100のL1Dキャッシュのヒットレーテンシは28~32サイクルで、P100、P4、M60の82サイクルと比較して大幅に高速化されていることが分かった。
右のグラフに見られるように、T4のL1Dはヒットの場合は32サイクル、L1ミスL2ヒットの場合は188サイクル、L2ミスでTLBヒットの場合は296サイクル、キャッシュとTLBの両方ともミスした場合は616サイクルのアクセスレーテンシとなっている。
-
T4、V100、P100、P4のL1データキャッシュのアクセスレーテンシを測定した。Pascalに比べてV100、T4のL1Dキャッシュは非常に速くなっている

(次回は4月12日に掲載します)