Turing GPUの新機能
Turing GPUはNVIDIAのGPUの最新のアーキテクチャであり、ILP(命令並列性)が改善されている。このため、
- 命令のエンコーディングが変更されている
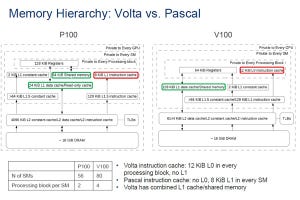
- 命令キャッシュ、データキャッシュの階層が改善されている
- レジスタファイルのポートの追加
- 依存性のある命令の発行レーテンシの低減
- シェアードメモリのアクセス時間の低減
- TLBのカバー範囲の拡大
が行なわれている。
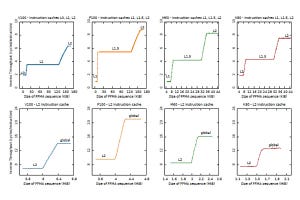
P4 GPUとT4 GPUを比較すると、T4ではL1/L2キャッシュやグローバルメモリのバンド幅が向上しており、マトリクス演算のスループットが向上している。
整数計算のためのuniformデータパスが追加
Turingでの一番大きな変更は整数演算用のuniformレジスタファイルが新設され、浮動小数点のデータパスと並列に動作できるようになった点である。これにより、インデックスの計算やポインタの計算がメインの浮動小数点の計算と並列に実行できる。このため、浮動小数点の演算がインデクスやポインタの計算に邪魔されることなく、最高の効率で実行できるようになった。
-
Turingでは整数命令のデータパスが追加された。これにより、インデックスやポインタの計算がメインの浮動小数点演算と並列に実行できるようになった

大部分の通常命令はuniformレジスタもregularレジスタもアクセスすることができる。一方、大部分のuniformデータパス命令はuniformレジスタだけが使え、regularレジスタは使えない。
そして、Turingでは64個のuniformレジスタが使える。1つのスレッドで使えるuniformとregularのレジスタの合計は最大256レジスタである。
-
Uniform命令はuniformレジスタだけが使える。Regular命令はregularとuniformの両方のレジスタが使える。1つのスレッドで使えるuniformレジスタは最大64個、両方の合計では最大256レジスタである

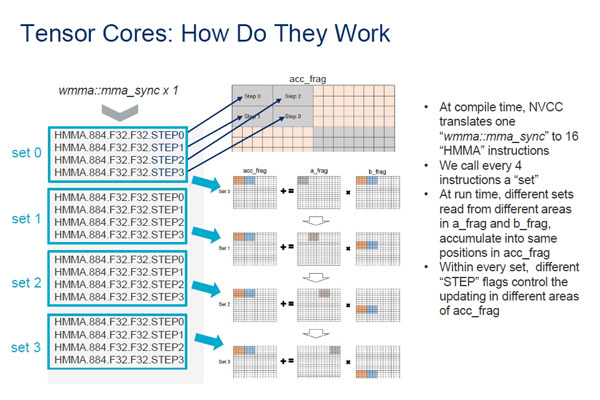
それから、NVCCコンパイラが改良され、マトリクス演算が簡潔に記述できるようになった。具体的には、半精度(16bit浮動小数点)のマトリクス演算を記述できるようになった。次の図のように、 wmma::mma_sync()に対してVoltaでは16個のHMMA命令を生成していたが、Turingでは4個のHMMA命令でできるようになった。
-
NVCCが改良され、半精度のマトリクス演算をだせるようになった。また、wmma::mma_sync()のケースではVoltaでは16HMMA命令を必要としたが、T4では4命令になった

命令のスケジューリングの改善
KeplerアーキテクチャからTuringアーキテクチャまでで、命令のスケジューリングが改善され、ハードウェアの効率が上がっている。次の図のように、Keplerでは7命令に対して64bitのコントロールが付加されていたが、Maxwellでは3命令に対して64bitのコントロール、VoltaとTuringでは1命令に対して1つの64bitのコントロールが付加されており、命令の中のコントロールの比率は上がっている。その分、ハードウェアをより細かく制御できるようになり、ハードウェアの効率は上がった。
図の下に、VoltaとTuringのコントロールのビットの使い方を示す。4bitがreuseのフラグ、6bitがwaitバリアのマスク、3bitがreadバリアのインデックス、3bitがwriteバリアのインデックス、1bitがYieldフラグ、4bitがstallサイクル数の指定に使われているという。
-
KeplerからMaxwell、Volta、Turingと変わるにつれて命令の中のコントロールの比率が増加している。その分、ハードウェアを細かく制御できるようになり、ハードウェアの効率が上がっている

(次回は4月11日に掲載します)