NVIDIAがDLAをオープンアーキテクチャで提供する理由
NVIDIAはHot Chips 30において「NVIDIA Deep Learning Accelerator(NVDLA)」を発表した。
-
Hot Chips 30にてNVDLAを発表するNVIDIAのFrans Sijstermans氏

NVDLAがこれまでの同社の製品と違うのは、それがオープンアーキテクチャであり、ハードウェアのRTLなどの設計情報から、ソフトウェア開発ツール、ランタイムサポートまでオープンソースで公開し、他社からの貢献も原則受け入れてコミュニティの標準を作り上げていこうというアプローチをとるという点である。そして、2018年3月にはArmの「Project Trillium」(コードネーム)の一部としてNVDLAを提供することを表明している。
-
NVDLAはXavierの開発の一部として開発され、CNNやコンピュータビジョンの処理に最適化されている。アーキテクチャやRTLをオープンソースとして公開する (出典:この連載の図は、Hot Chips 30におけるNVIDIAのFrans Sijstermans氏の発表スライドのコピーである)

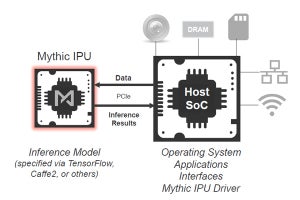
NVIDIAが公開するNVDLAハードウェアは、広い適用範囲をカバーできるようにパラメタ化されたディープラーニングのアクセラレータの設計と開発環境などである。Xavierに組み込まれたDLAは、1つのセットのパラメタを選んだ実装であり、NVDLAの1つの具体例であるが、これだけがNVDLAの製品ということではない。
IoTなどのエッジデバイスでのディープラーニングのアクセラレータは、どこまで適用範囲が広がるのか分からない将来性のある分野であり、NVIDIA独自で開発するよりも、オープンソースで皆で盛り上げて、広い市場をカバーして行く方が得策とNVIDIAが判断したということであろう。ライセンス料を取るわけではないので、NVDLAが使われても直接、NVIDIAにお金が入るわけではないが、業界標準を押さえていれば、何かと便利で、NVIDIAのビジネスにプラスになることがあると思われる。
画像認識で多く用いられるCNNとは
エッジデバイスで多く使われると考えられる画像認識などでは、次の図に示すようなCNN(Convolutional Neural Network)の推論(Inference)が主な処理になると見られる。
CNNの推論処理は、簡単に書くと次の図の左から猫のピクセルイメージを入力し、conv1の畳み込み処理を行い、さらにconv2の畳み込み処理の結果を全対全結合のfull1とfull2層を通して、このイメージは猫であると認識する。実際には2層の畳み込み処理では不足で、もっと多くの層が必要であるが、この図は単純化して描かれている。
畳み込み処理は3×3とかの比較的狭い領域の特徴を抽出することができ、例えば縦縞とか横縞とかを取り出す。Conv2はconv1の出力の比較的狭い領域の特徴を抽出し、conv1の抽出した特徴のまとまりを抽出する。
荒っぽい説明であるが、階層的に畳み込みを行っていくと、より広い領域の特徴を抽出することができ、4層、5層になると、目らしきもの、口らしきものなどが抽出されてくる。そして、全対全層で目らしきものと口らしきものがあり、三角の耳らしきものが揃って抽出されていれば、これは猫らしいという感じで画像を認識する。
-
CNNの推論はConvolutional(畳み込み)層とFully connected(全対全)層を使って行われる

畳み込みは、W×Hのイメージで、各ピクセルがC(例えばRGB画像の場合はCは3)の値を持つ入力画像(Input Activations)にR×S×C(例えばRとSは3などの小さい数)のフィルタを掛ける。なお、フィルタの各要素の値は、学習で決められた値で、推論の最中では値は変わらない。
畳み込み処理は、入力のR×S×Cの領域を取り出し、入力と対応するフィルタの要素の値を掛け、積の総和を出力とする。つまり、R×S×C要素の情報を1要素に畳み込む。
そして、入力画像の位置を右に1要素ずらせて同じ計算を繰り返して、隣の出力要素の値を計算する。これを繰り返してConvolution Resultと書かれた面全体の要素の値を計算する。
ここでK個のフィルタでこの計算を繰り返すとW×Hの面がK枚作れる。これを重ねたのが次の図のConvolution Resultである。これに対して、小さな領域の要素の中の最大値の要素を出力とするMax-Poolingや非線形のアクティベーション関数を適用して出力を得る処理などのPost-Processingを行って、1つのConvolution層の処理が終わる。この出力はOutput Activationsとも呼ばれる。
-
Convolutionはフィルタの要素と入力の対応する要素の値を掛け、それらを合計して出力要素の値を決める。これを繰り返して1つの出力面を作る。K個の出力面を重ねたものが畳み込みの出力となる。さらにポスト処理を行って出力が得られる

(次回は9月19日に掲載します)