クロスコンパスのディープラーニング
クロスコンパスは東京工業大学(東工大)発のベンチャーで、東工大の人工知能研究を商業化するために2011年10月に設立された会社である。しかし、2012年のILSVRCでのSupervisionの圧勝をみて、ディープラーニングの調査を始め2013年からは独自の実装を開始した。そして2014年になると、あちこちからディープラーニングのパイロットプロジェクトや研究開発の依頼が舞い込むようになり、ディープラーニングの仕事が増えてきたので、2015年4月10日にクロスコンパス・インテリジェンスを立ちあげたという。
|
|
|
クロスコンパス・インテリジェンスの技術について講演する佐藤CTO |
今回のNVIDIAディープラーニングフォーラムにおいて、佐藤聡 CTOが同社の状況と技術について講演を行った。
同社は色々な開発を行っているのであるが、依頼元との契約で公表できないものが多く、今回の発表では、公開データを用いた物体認識と動作認識の実験結果と、同社の「Intelligence Exchange」の説明などを行った。
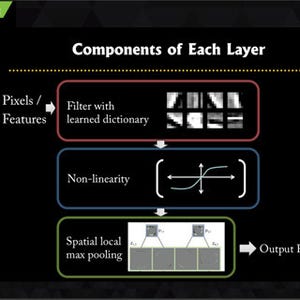
次の図はILSVRC2012の一部のデータを使い、ネットワークの構造が正答率にどのように影響するかを見た実験で、左側は隠れ層のノード数が約1万、その半分、1/4とした場合、正答率は57.6%、50.6%、47.0%と、ノード数が減るに従って下がっている。右側は層の構成を変えた場合の実験結果で、この中では構造2が正答率57.8%で一番成績が良い。
しかし、HintonなどのSupervisionは85%近い正答率であり、実験に使ったネットワークは比較的簡単なもののようである。

|
|
ILSVRC2012の一部のデータを使って、隠れノード数や層の構成が正答率にどの程度影響するかをみた実験の結果 |
次の図はNVIDIAのTesla K40 GPUとTitan Xを用いたシステムでの学習時間の比較で、10クラス、1万2524枚の画像を学習している。隠れ畳み込み層は5層(構造4は3層)で、隠れ全結合層数を0~2と振っている。一番複雑な5-2層の構造をK40 GPUを使って学習した場合の学習時間は約120分となっている。
同じ学習をGeForce Titan X GPUを使うと約75分となり、これはTitan Xの方が演算性能が高いことによる。更にcuDNN v2を使うことにより約45分に学習時間が短縮され、cuDNNの使用で70%程度性能が向上していることが分かる。

|
|
10クラス、12,524画像の学習時間。K40 GPUでは約120分、Titan X GPUでは約75分、それにcuDNNを使うと約45分に短縮できる |
次の実験は、左からウォーキング、ジョッギング、ランニング、ボクシング、手を振る、手を打つという動作をしている人のビデオから動作を認識するというものである。次の図の縦方向の4枚は、屋内、屋外や照明や服が異なるものとなっている。これらの6動作を4環境で4回繰り返して入力データを作っている。これを25人について記録したKTHデータベースを入力として使っている。

|
|
左からウォーキング、ジョッギング、ランニング、ボクシング、手を振る、手を打つという動作をしている人のビデオから動作を認識する |
ビデオから時系列データを作成し、8人のデータを学習用、8人のデータを検証用、残る9人のデータをテスト用として使用した。右下の表は小さくて見えにくいが、例えばボクシングの画像は学習用が10,808フレーム、検証用が8,945フレーム、テスト用が10,407フレームとなっており、移動の速いジョッギングはそれぞれ4,000フレーム程度、さらに速いランニングは2,000フレーム程度のデータ量となっている。また、時系列でない静止画像のデータも作成した。

|
|
6動作のビデオから時系列のデータを作る。学習用8人分、検証用8人分、テスト用9人分に分割した。フレーム数はそれぞれ2,000~13,000である |
静止画像による正答率は62.97%であったが、時系列画像を使った認識では79.72%の正答率となり、やはり、時系列画像の方が動作の違いを認識しやすいことが分かる。
時系列画像を使った実験の結果は、次の図の右上の表にまとめられており、この表は縦方向が認識した結果で、横方向は正しい結果である。例えば、ボクシングは1900サンプルの内、正解が1815サンプルであったが、ウォーキングは、正解は1463サンプルに留まり、420サンプルではジョッギングと誤認識している。

|
|
上の表が時系列データの認識結果と正解のまとめ。下の左側の2つのグラフは静止画像の学習データとテストデータの分布、右側は時系列画像の学習とテストデータの分布。点の色が異なるデータを表す |
認識システムの学習には同じネットワークを2つ使い、両者の結果を比較するシャム双生児型のネットワークを使った。ペアにしたデータ画像を入力し、ラベルが一致している場合は、距離を0に近づけるように学習を行う。そして認識を行う場合は、片側だけを使う。

|
|
同じ構成のネットワークを2つ使って比較を行い、ペア画像のラベルが一致すれば距離が0になる方向に学習を行う |
例えば、防犯カメラの画像から不審な動きをする人物を見つけるとか、機械の稼働状況から異常を早期に発見するなど、異常なパターンの検出は、ディープラーニングの応用として期待の大きい分野である。ただし、異常な動きは出現頻度が低く、異常データを学習させるのが難しいという問題がある。例えば、センサのデータをオートエンコーダを使って教師なし学習を行うなどの方法が考えられるが、どのようなネットワークを使うのが最適かを見極める必要があるという。

|
|
異常検出はディープラーニングシステムの用途として期待が大きい。しかし、どのような構成のネットワークがよいかを見極める必要がある |
そして、クロスコンパス・インテリジェンスでは、これらのディープラーニングシステムの開発に加えて、学習済みのネットワークを部品として流通させる仕組みの提供を考えている。同社では、これを「Intelligence eXchange(略してIX)」と呼ぶ。コアとなるDeep Learningシステムをベースにして医療、建設、販売、教育など、それぞれの分野の学習済みネットワークを揃えて流通させるという構想である。半導体の設計では、流通するIPコアを組み合わせてSoCを設計することは常識であり、同じことがディープラーニングの世界でも実現できればメリットは大きいと思われる。

|
|
クロスコンパス・インテリジェンスでは、学習済みのネットワークを部品として流通させる仕組みの提供を考えている |
佐藤氏は、最後に同社の認識システムのデモを行った。次の図はパソコンに接続したUSBカメラで会場を撮影した画像をリアルタイム認識するもので、左のイメージの認識結果を右側の窓に表示している。この例では第一候補はspotlight、spotであり。青いバーで表示されたスコアは約0.5である。第2候補はstageで0.3強のスコアとなっている。3位以降はスコアが低く問題外という候補である。この例ではかなり正しい認識を示しているが、カメラが逆さまになり、壁面の連なった照明だけが写ったりするとgreat white sharkなどという第1候補が出たりするのはご愛嬌であった。

|
|
リアルタイムの認識デモ。約0.5のスコアでspotlightが第1候補になっている。第2候補はstage |
このように国内でも、先進ベンチャー企業はディープラーニングに取り組んでいるが、米国のネットジャイアントと比較すると国内の大企業の取り組みは見えておらず、遅れているのではないかと懸念される。東大の松尾先生の指摘のように、日本にもチャンスはあるので、頑張って貰いたいところである。