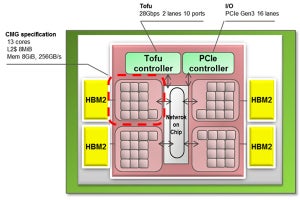
A64FXではリングバスにも工夫がある。4つのCMGとTofu、PCIe、そして割り込みコントローラを繋ぐ2重リングだけでなく、CMG0とCMG1をつなぐリンクとCMG2とCMG3をつなぐリンクが追加されている。
-
リングバスは、115GB/s×2のバンド幅。CMGやI/Oを接続するリングバスは単純なリングではなく、CMG2と3、CMG0と1をつなぐリンクが追加され、CMG間の通信レーテンシを短縮している

単純なリングの場合は、CMG2とCMG3の通信とTofuからCMG1への通信が同じ通路を使うことになりコンフリクトが起きる。また、CMG2とCMG1の通信は割り込みコントローラのリングストップを経由するのでパスが長くなってしまう。
クロスバにすれば、このような問題はないが、物量が多くなってしまう。このため、右の図のようにCMG2と3、CMG0と1のリンクを追加してCMG間の通信とTofuネットワークを使う通信のコンフリクトの問題を解決した。
-
単純なリングバスでなく、CMG2と3、CMG0と1を接続するリンクを追加し、Tofuの通信コンフリクトを解消し、CMG間の通信性能を改善した

次の図はS64 XIfxの性能で正規化したA64FXの性能を示している。倍精度浮動小数点での行列積を計算するDGEMM性能は2.5TFlopsとなり、2.5倍の性能、メモリバンド幅が効くStream Triadは840GB/sとなり、約3倍の性能となっている。流体、気象、地震解析などの実アプリでは2.8倍から3.4倍の性能となっている。また、AI関係のジョブではFP32での計算では2.5倍、INT8で処理できるものでは9.4倍の性能となっている。
-
DGEMMは2.5TFlops、Stream Triadが840GB/sとなり、他のアプリケーションでもS64 XIfxの2.5倍から3.4倍の性能。INT8で済むAIの計算では9.4倍の性能が得られた

A64FXでは、アプリケーションから消費電力をコントロールできるように、パワーノブという機能を設けている。パワーノブは、次の図でオレンジに塗られたブロックの動作を可変する。例えば命令のデコードを4命令並列から2命令並列に切り詰める。あるいは動作させる演算器の数を減らすという風にする。
-
アプリケーションから電力をコントロールするPower Knobという機能を設けた。そのアプリケーションでは必要性の低いユニット(オレンジ色のユニット)の並列度を減らして消費電力を低減する

7nm世代のLSIでは配置配線のプロセスルールが細かく複雑になり、設計が難しくなったが、アーキテクチャや論理設計といったフロントエンドの設計と、配置配線、電力設計などのバックエンドの設計を連携させ、細かくフィードバックを掛ける設計手法を取ることで、高い性能/電力を実現することができたという。
-
フロントエンドの設計とバックエンドの設計を緊密に連携させ、細かくフィードバックを掛ける設計手法で、性能/電力を改善することができた

A64FXは世界初のArmv8-A SVEアーキテクチャのプロセサである。そして富士通が開発してきたマイクロアーキテクチャにより、HPCとAI分野で高い性能と高い性能/電力を実現している。また、論理設計と物理/電力設計の統合は高い性能と低電力の両立を実現した。
-
A64FXは世界初のArmのSVE命令をサポートしたプロセサである。命令アーキテクチャはArmであるが、中身は富士通のマイクロアーキテクチャを使って高性能と高い性能/電力を実現した。また、論理設計と物理/電力設計を密接に連携させることで高い性能/電力を実現している

富士通は、開発するプロセサごとに設計チームがあるのではなく、メインフレームのプロセサもSPARCプロセサも、今回のArmプロセサも1つのチームで全部の開発を行っているという。このため、すべてのプロセサの基本的なマイクロアーキテクチャは同じで、機械命令が異なる点やSVEのベクタ命令を処理するハードウェアだけの追加でA64FXを作ったという。つまり、A64FXはArm命令アーキテクチャという衣をかぶっているが、中身は、富士通が改良を続けてきたプロセサのマイクロアーキテクチャで作られている。
今回、初めてArm命令アーキテクチャのプロセサを作ったわけで、何か難しい点や困ったことはなかったかと山村氏に質問したのであるが、特に問題はなかったという回答であった。