大学とのタイアップで、色々なプログラムがMaxeler用に開発されたり、移植されたりして、現在は60種類以上のプログラムを含むAPPGALLERYができている。

|
|
60種類以上のプログラムを含むAPPGALLERYができている |
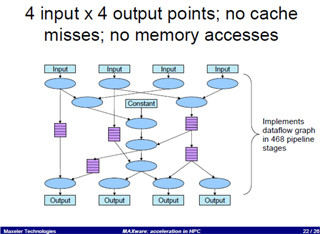
これまでのDFEはFPGAで作られていたが、これまでの経験からデータフロー型のソフトウェアの蓄積もでき、どういうハードウェア機能が必要かということが分かってきたので、専用のLSIを作ることにしたという。
チップは中央に4つのコア領域があり、周囲をプログラマブルメモリコントローラ(PMC)、チップ間を接続する高速リンク(MAX-R)、チップ内のクロックや電源を制御するMGRなどが取り囲んでいる。中央のコア領域は計算コアであるDense Arithmetic Unit(DAU)とメモリブロック、Generic Reconfigurable Logic(GL、FPGAのロジック)とそれらを制御するProgrammable Chainable Counter(Sと書かれており、シーケンサ相当)などで構成されている。
そして、これらのブロックの間を4bit(Nibble)単位で構成が変更可能なインタコネクトで結んでいる。このインタコネクトは一定以下の遅延時間となるようにパイプライン化されており、FPGAで問題となる、長い配線が出てきて目標クロックを達成するのに苦労するという問題が起こらないようになっている。
なお、コア領域のDAUなどの配列は…が書かれており、実際の個数は図よりも多い。

|
|
Maxelerのデータフローチップのブロック図 |
DAUは10台のData Flow Processor(DFP)と入力用、出力用それぞれの大容量メモリ(LMEM)からなっている。LMEMはDIMMやHMCなどの汎用DRAMを使う。DFPは複数の高速メモリユニットを内蔵しており、これらはFIFOあるいはスクラッチパッドメモリとして使われる。
DFUはデータフロー処理の1つのオペレーションを割り付ける単位で、LNS表現の40bitのデータを処理するMACとバレルシフタを持っている。

|
|
Dense Arithmetic Unitのブロック図 |
DDRメモリのアクセスは1回500pJ、1mmの配線のデータ伝送は6pJ、20mmの配線は120pJ、浮動小数点の演算は10pJと見込み、8Bの処理に2000オペレーションを必要とすると、50GBの入力データを処理するのに必要なエネルギーは69.62Jとなる。これを3秒で行うとすると消費電力は23Wとなると見積もられる。

|
|
50GBの入力データを3秒で処理する場合の消費電力は23W |
14nmプロセスを使い、チップを20mm角とすると、浮動小数点演算器を15,000個程度搭載できる。ローパワープロセスを使い、演算あたりのエネルギーを5pJに抑え、これを500MHzで動かした場合の消費電力は37Wと計算される。これにI/Oやメモリの電力を加えるとデータフローチップの消費電力は50~65Wになると予想している。

|
|
14nmプロセスを使えば15,000個の浮動小数点演算器を集積でき、これらを500MHで動かした場合、データフローチップの消費電力は50~65Wと予想している |
そして、第1世代のデータフローチップでは、性能ではFPGA版の10倍、パイプライン化して動作周波数を保証した配線の採用で配置配線の設計期間は1/10、 TCOは1/10の実現を目指しているという。

|
|
第1世代のデータフローチップでは,FPGA版の10倍の性能,1/10の配置配線時間,1/10のTCOの実現を目指す。 |
また、第2世代のデータフローチップではアクティブインタポーザを使って、CPUと一緒に実装することも視野に入れているという。

|
|
アクティブインタポーザを使いCPUと一緒に載せる第2世代データフローチップの構想 |
データフローチップは、FPGA版と比べるとカスタム設計となるので、DAUの消費電力を減らし、チップ面積も小さくできそうである。この点で並列度の高い計算を行なう部分の効率を高めることはできそうである。
しかし、CPUで処理した方が効率が高い部分は残るので、CPUとデータフローチップの間のデータ転送を含めてどの程度の性能が出せるのか、それがGPUなどを使う処理に比べてどの程度優位となるのかなどが問題になると思われる。