前回はChatGPTが流行した背景について説明しました。今回はChatGPTの技術的な成り立ちについて、その概要をわかりやすく解説します。日々の業務においてAIの適切な利用を実現するために、そのメカニズムを理解して、ChatGPTは何が得意であり、何が苦手かを把握しましょう。
基盤となる「GPTモデル」の特徴とは?
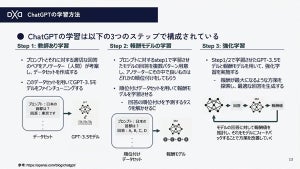
まずは、ChatGPTの核となる「GPTモデル」と呼ばれる言語モデルについて説明します。言語モデルとは「文章の中で次に並ぶ言葉を確率的に予測するモデル」のことを指します。例えば、昔話で「むかしむかし」という言葉を聞くと、次に「あるところに」という続きが思い浮かぶでしょう。さらにその次には「おじいさんとおばあさんが」、その続きは「いました」という単語がついつい浮かんでしまうでしょう。
これと同じように、言語モデルは次に表示する可能性の高い文章を確率的に予測し、自然な文章を生成することができます。そもそも、GPTとは「Generative Pre-trained Transformer」(生成を事前学習したニューラルネットワークアーキテクチャ)の略です。
GPTはインターネット上にある大量のテキストデータをもとに、「自己教師あり学習」という方法で学習しています。例えば「日本の首都は〇〇である」という穴あきの文章から「日本の首都は東京である」という文章を生成できるように学習していきます。
この学習方法により、GPTモデルは膨大なデータから自然な文章を生成する能力を身につけています。ChatGPTの基盤であるGPTモデルの特徴は、「言語パターンを学習し、確率的に自然な文章を生成する能力」にあるといえます。しかしこれだけではChatGPTの性能にはまだ及びません。次に「強化学習」について解説します。
高い精度の実現に寄与しているのは「強化学習」
2020年7月に発表されたGPT-3は1750億個のパラメータを持つ巨大なモデルで、生成される文章が人間によるものとほぼ見分けが付かないほどの精度に到達しました。このGPT-3に対し、差別や偏見を減らし人間の好みに合う表現をするように調整(アラインメント)することでInstructGPTが生まれ、さらに会話に特化したデータでファインチューニングを行うことによってChatGPTが誕生しました。
-
ChatGPTの技術構造

対話型AIというものは過去にも存在しましたが、それらよりも人間らしい会話ができるようになった背景には「強化学習」の存在があります。
過去の対話型AIの一例を挙げると、2016年に公開されたMicrosoftのAI「Tay」はTwitter上のつぶやきから学習を行った結果、数日で差別的な発言を始めたので公開が中止される事態になりました。この事例から、単にAIにデータ学習させるだけでは不十分で、学習部分を一般のユーザーに委ねることにはリスクが伴うことが明らかになりました。
そこで、ChatGPTにはRLHF(Reinforcement Learning from Human Feedback:人間のフィードバックによる強化学習)という学習方法が用いられています。この仕組みは、まずAIモデルに入力した指示文(プロンプト)からいくつかの回答を得て、その回答に人間が得点を付けます。さらに、AIの出力したテキストをこの得点を基に評価するモデルを作り、採点をさせるというものです。
つまり、どのような結果を出せば高い得点がもらえるのかというルールを明確にした上で、AIにより高い点数を取らせるゲームを行わせることで、人間の好みを理解させるという手法を用いたのです。
-
RLHFの仕組み(OpenAI公式ブログより)

このようなプロセスを経ることで、膨大な文章パターンを学習し、それを人間の手によるフィードバックで微調整・会話に特化した調整を行い、ChatGPTという高度に人間らしい会話を行うAIが誕生しました。
ChatGPTは大量のテキストを学習し高度な対話文章を生成できますが、上述のように確率的に文章を生成するという特性のため、常に正確な回答を返すとは限りません。そのため、生成した文章は人の手によるチェックが必須です。
また、2021年9月のデータを使い学習させているモデルがベースになっているため、最新の情報に関する質問に対して正しく回答ができない場合があります。「今日の天気は?」等の質問には回答できません。プラグインなどの活用により弱点を補う方法もありますが、まずは基本としてこうした点を理解しておきましょう。
ビジネスパーソンの身近でも使われている「機械学習」
ここまでは、ChatGPTについて技術的に説明してきました、このように、コンピュータに人間の言葉、つまり自然言語を理解させる取り組みは古くから研究されてきました。これをNLP(Natural Language Processing:自然言語処理)と呼びます。
NLPの範囲は広く、その中でも機械自身が学習を行う「機械学習」は最近のサービスにおいて特に多く用いられています。例えば迷惑メールのフィルターや、英語を日本語に翻訳する機械翻訳、文字変換予測、AlexaやSiriなどのAIスピーカーなど、私たちの生活を豊かにする多くのサービスで活用されています。
これらのサービスが示すように、私たちの日常生活には気付かないうちに機械学習が深く浸透し、それらによって生活が支えられています。ChatGPTのような生成AIの登場により、私たちは複雑なプログラミングを行わなくても機械と簡単にコミュニケーションを取れるようになりました。
プライベートな環境では、生成AIが友人のような役割を果たし、なんでも相談できる存在になるかもしれません。特にビジネスシーンではこれから多くのサービスが生成AIを活用することが予想されます。
私たちが機械学習を使ったサービスを意識せずに日常で活用するのと同様に、生成AIが私たちの生活に溶け込むことは間違いありません。そのため、今のうちからChatGPTを使った新しい仕事の進め方に慣れ、適応していくことが重要となるでしょう。