電力消費の削減技術
マシンラーニングの計算では、入力や重みがゼロになっているケースが多くあり、このような場合に積を計算するのはムダで、ムダに電力を消費する。そのため、Arm MLPでは入力がゼロの場合はデータパスの動作を止めている。これにより、~50%の電力低減ができるという。
-
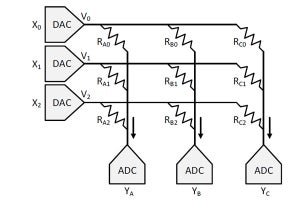
MACエンジンは2×8×16=256ops/cycleの演算ができ、チップ全体では4096ops/cycleとなる。1GHzクロックの場合、4.1Topsの演算ができる

MAC Engineは16Wideの内積計算を行う演算器を8個もっている。他のCEから送られてきた計算結果はBroadcast Networkで組み立てられて次の畳み込み演算の入力となり、CEの中のすべての16wideの内積演算器に送られる。
-
CEは16wideの内積演算器を8個もっている。他のCEからの出力はBroadcast Networkと書かれたブロックで組み立てられて入力となり、すべての内積演算器に送られる

個々のOFMの計算に使われる重みは圧縮形式でSRAMから読み出され、Weight Decoderで元の形式に戻してMAC Engineに供給される。
-
OFMを計算するための重みは圧縮形式でSRAMに格納されており、重みの読み出しを行うとWeight Decoderで圧縮を元に戻す

POP IPは16nmと7nmのものを用意
Armが物理設計を最適化したMLPのPOP(Processor Optimization Package) IPは16nmと7nmプロセス用が提供される。POP IPを使うと、チップ面積は40%小さくなり、消費電力を10~20%低減することができる。
-
Armが物理設計を最適化したPOPは、チップ面積が40%小さくなり、消費電力は10-20%低くなる

必要なバンド幅の削減という点で、重みと入出力のデータ圧縮は重要である。次の図のパイチャートはArm MLPの消費電力の内訳を示している。MLPの消費電力が一番多いが、入力をDDR DRAMから読み出す電力、重みをDDR DRAMから読み出す電力も合計すると全体の40%程度を占めている。
また、OFMの計算に使う重みをSRAMに収めて外部のDRAMをアクセスする回数を減らすためタイリングを行っている。ということで、必要なバンド幅を低減するため、Arm MLPでは入力と重みの圧縮とタイリングをサポートしている。
-
入力の読み出しと出力の書き出しのためのメモリアクセスに必要な電力は、MLPの動作電力と同程度と大きい。このため、データの圧縮を行っている。また、出力の計算に必要な重みだけをSRAMに格納するためタイリングを行っている

次の図は横軸が8×8のブロックの中のゼロの数、縦軸がブロックの中のユニークな非ゼロの数であり、そのようなデータ値が何個あるかを棒グラフの高さで示している。
右下に高い棒グラフが集まっており、ゼロが非常に多く、ブロック内のユニークは非ゼロの数も小さいことを示している。左端はゼロの数は0個であるが、ユニークな非ゼロの数はそれほど多くなく、同じ値が何度も現れていることを示す。そして、右から1/4あたりにある瘤は、フィルタの適用にあたってフィルタがはみ出さないように、入力の周囲をゼロで埋めるパディングによるものである。どれもある程度の規則性があり、それを利用した圧縮が可能である。
この状況で8×8のブロックに対して圧縮を行うと、Inception v3ネットワークの場合、ロスレス圧縮で、平均的に3.3倍の圧縮率を得ることができた。
-
Inception v3の8×8のブロックに含まれるゼロの数とユニークな非ゼロの数の分布。右端のゼロの数が多いブロックが多数存在する。左端はゼロの数はほとんどないが、ユニークな非ゼロの数は少なく、これも圧縮の可能性がある

次の図の右側の上の図は、Inception V4ネットワークの各層の入力と重みのデータ量を示すグラフである。このグラフを見ると、入力のデータ量は後の層になるとデータ量が減り、一方、重みのデータ量は後の層になるほど増えている。このグラフの縦軸は対数軸であるので、パッと見たところ大きく増えている印象は無いが、入力で言えば20KBくらいから1000KB程度まで変化している。
プルーニングは値がゼロに近い重みをもつ入力枝を削除し、すべての入力枝が削除されたらニューロンも削除してネットワークを簡略化するという変形であり、計算量を減らすことができる。
この圧縮はオフラインで行われ、クラスタリングとプルーニングの両方が適用されている。
-
重みの小さい枝を刈り込むプルーニングは、計算を必要とする枝の数を減らす。クラスタリングは、非ゼロの重みの値の種類を減らす

(次回は9月21日に掲載します)