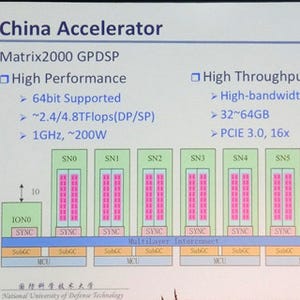
通常、Xeon Phiは61コアであるが、Tianhe-2で使用したXeon Phiは初期チップであるので、歩留まりに問題があり、57コアしか使えないとのことである。それでも16個の倍精度浮動小数点の演算を1サイクルに16回行うことができる。
-
図4 Xeon Phi側のボードを引き出したところ。このボードには5個のXeon Phiが搭載されているはずであるが、1個はボードの引き出しの関係で、この写真では隠れている

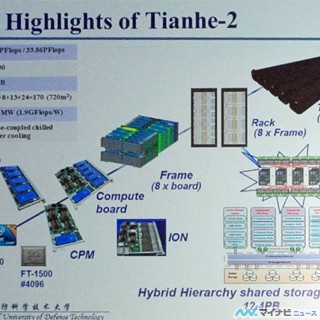
Xeon Phiは1.1GHzのクロックの場合、ピークで1.003TFlops/sの演算ができ、2個のIvy Bridgeがそれぞれ0.2112TFlops/s、3個のXeon Phiがそれぞれ1.003TFlopsであるから、ノード当たり3.431TFlopsの演算能力となる。これを16,000ノード接続するとピーク演算性能は54.9PFlopsとなる。
ラックを図5のように並べると、設置面積は720平米となる。ただし、NUDTのコンピュータルームは狭く、最適な配置ができない。
-
図5 NUDTのセンターに置くときのレイアウト。ネットワーク用の薄緑のラックが分散されて置かれている

システムが広州市のセンターに移設されたら、図6のように、最適な配置とすることができるようになる。
-
図6 広東市のスパコンセンターに設置された状態の想像図

各ノードは64GBのメモリを持ち、Xeon Phiは8GBのメモリをもっているので、ノード全体では88GBのメモリを持っている。したがって、Ivy Bridge部分が1.024PB、Xeon Phi部分が0.384PBで、システム全体では1.404PBのメモリを持っている。