Thinking Machinesの「Connection Machine」
1982年、アメリカ東海岸のマサチューセッツ州にDaniel Hillis氏とSheryl Hander氏らによって、Thinking Machinesというスパコン会社が設立された。Hillis氏はMITのポスドクで、Marvin Minskyの研究室でAIを研究しており、LISPによるシンボリック処理を高速に並列実行するマシンを開発しようとしていた。Daniel Hillis氏はマシンの開発を担当し、友人のSherly Handler氏はCEOとして経営を担当した。
Thinking Machines社(TMC)の「Connection Machine」はSolomonのようなビットシリアルな演算を行う多数のPEを持つ超並列のマシンである。
TMCはDARPAの資金を得て、最初の製品である「CM-1」を開発し、1985年に製品化した。CM-1の計算を行うデータプロセサは、図3.7に示すように、1ビットのALUとビット単位でアクセスできる4Kビットのメモリを持つ。そして、16個のデータプロセサとデータのルーティングを行うルータを1チップに集積し、4096チップで64K個のデータプロセサを持つCM-1を構成していた。また、メモリは4KビットのSRAMチップで作られていた。
なお、このチップのサイズはおおよそ1cm2で5万個のトランジスタを集積していた。そして、4MHzのクロックで動作し、消費電力は1W程度であった。
-
図3.7 Thinking Machines社のデータプロセサ。16個のデータプロセサを集積したチップを4096個使用し、64KデータプロセサのCM-1を構成した (出典:IEEE Computer、Aug.1988)

メモリから2つのオペランドを読み、1ビット分の演算を行い、結果をメモリに書き戻すという動作を行うので、1ビット分の演算には0.75μs掛かり、それに命令のフェッチとデコードの時間が掛かった。そのため、32ビットの整数の加算には24μs掛かり、CM-1全体の加算性能は、おおよそ2G演算/秒であった。
1ビット演算器によるシリアル演算は、桁数nに比例して演算時間が長くなるが、n倍のプロセサが作れれば、n桁の演算器を使う場合とスループットは同じである。演算器だけで言えば、キャリールックアヘッドなどのロジックが不要な分、ハードウェアを簡素化できる。また、固定の語長の演算を行う必要はなく、必要な長さの演算だけを行えばよいのでその分、スループットを向上させられる。
しかし、並列に実行するスレッド数がn倍になり、それらのスレッドの状態を保持するためのメモリがn倍必要になるという不利な点もある。
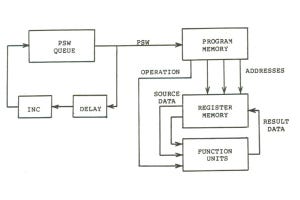
図3.8はCM-1の全体構成を示す図で、64K個のデータプロセサは4つのブロックに分けられ、それぞれにシーケンサを持っている。シーケンサは同じ命令をブロック内の16K個のデータプロセサに供給するSIMDアーキテクチャとなっている。
そして、4つのデータプロセサブロックと4台のフロントエンドコンピュータ(DEC VAXあるいはSymbolics)がNexusというクロスバ経由で接続されている。また、各データプロセサブロックからConnection MachineのI/Oシステムが接続されており、そこから、高速ストレージである3台のData Vaultと1台のグラフィックディスプレイに繋がっている。
なお、CM-1の物理的なプロセサ数は64Kであるが、それぞれのプロセサを時分割で最大16の仮想プロセサに分割して使うことができるようになっていた。解くべき問題のサイズによっては64Kプロセサに均等に仕事を割り当てることが出来ない場合があるが、仮想プロセサの分割を変えることにより、各プロセサの分担をより平等にするというような使い方が考えられていた。
-
図3.8 CM-1システムの全体構成 (出典:IEEE Computer、Aug.1988)

(次回は11月1日に掲載します)