GPUメモリから通信アダプタへのデータ転送
スパコンのように大規模なコンピュータでは、CPUに何台かのGPUを接続したものを計算ノードと呼び、これらをInfiniBandなどの高速のネットワークで接続するという構成をとるのが一般的である。なお、仮想記憶を使うCPUでは、メインメモリのページは外部記憶(HDDやSSDなどのストレージ)にスワップアウトされる可能性があり、GPUとのDMAを行うタイミングでメインメモリのページがスワップアウトされてしまい、メインメモリ上に存在しなくなってしまうと困ったことになる。このため、DMA転送用のバッファなどは、通常、スワップアウトを禁止するピン止めページとして割り当てを行う。また、GPUも仮想記憶を使っているので、物理アドレスが変わってしまう可能性がありピン止めを必要とするが、ここでは明示的な説明は省略している。
図3-57に示すように、普通は、GPUの処理結果を、CPUが赤線で示すDMA転送で自分のメインメモリのピン止めされたGPUデータ領域に取り込み、次に青線で示すようにそのデータをメインメモリのピン止めされたInfiniBandアダプタ(NIC)領域にコピーする。
それから、InfiniBandのネットワークアダプタのDMAを起動して、そのデータをネットワークカードにコピーし、NICが他のノードにデータを送るという手順をとる。しかし、この方法では、 GPUのデータ領域とInfiniBand用データ領域のCPUによるコピーと、メインメモリを経由する2回のPCI Expressの転送が必要となる。

|
|
図3-57 通常のGPUデバイスメモリからNICのバッファへのデータ転送 |
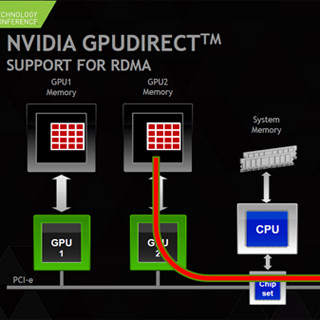
これに対して、NVIDIAとMellanox(InfiniBand NICの最大手メーカー)は共同でGPU Directという仕組みを開発した。Version 1は、ソフトウェアを改良して、メインメモリの中でのGPU用とInfiniBand NIC用のピン止めメモリを共用としてコピーを省いただけのものであるが、Version 2では、同一のPCI Expressバスに接続されているGPUのデバイスメモリから別のGPUのデバイスメモリへのデータ転送がCPUのメインメモリを経由せず、本当にダイレクトに転送できるようになった。Version 2を使えるGPUは、PCI ExpressのPeer-to-Peer通信機能を使って、同じPCI ExpressのRoot Complexの下に繋がっているGPUの間での通信を行っている。なお、GPU Direct v2が使えるのはFermi以降のGPUである。また、GPU Direct v2を使うにはバージョン4.0以降のCUDAが必要である。
CUDA 4.0ではUnified Virtual Addressing(UVA)がサポートされており、次の図の右側ように、1つのノードのメインメモリとすべてのGPUのデバイスメモリは1つのドレス空間に配置されており、GPUのデバイスメモリとメインメモリの間の転送を行うDMAハードウェアでデータの転送ができる構造になっている。

|
|
図3-58 GPU Direct v2ではUnified Virtual Addressingを使う。UVAでは、メインメモリ空間にGPUのデバイスメモリが配置され、メインメモリと同じにアクセスできる |
GPU Direct Version 3は、同じRoot Complexに繋がるGPUとInfiniBand NICとの間をPeer-to-Peer通信でデータ転送を行い、他のノードのInfiniBand NICとの間はInfiniBandのRemote DMA機能を使って通信し、さらにInfiniBand NICとGPUの間をPCIeのPeer-to-Peer通信で繋いで、異なるノードのGPUのデバイスメモリ間での直接のデータ転送を実現している。なお、GPU Direct v3を使うためにはMellanoxのConnecti X3以降のInfiniBand NICが必要である。

|
|
図3-59 GPU DirectによるGPU間の直接DMA転送 |