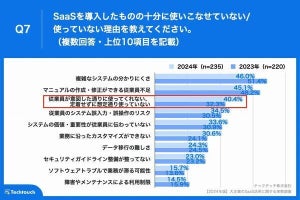
今回は、順位(ランキング)を調べるときに役立つ関数について紹介していこう。データの「並べ替え」により順位を求める方法もあるが、同じ数値データが複数あると、少しだけ厄介な問題が発生する。こういった状況にも対応できるように関数RANKの使い方を覚えておくとよい。あわせてLARGEやSMALLといった関数の使い方も紹介しておこう。
ランキング(順位)を求めるオーソドックスな方法
数値の大きい順(または小さい順)に順位を付けて、ランキング形式の表を作成したい場合もあるだろう。そこで今回は、順位(ランキング)に関連する関数として、RANK、LARGE、SMALLといった関数の使い方を紹介していこう。
-
順位を求める関数RANKとLARGE、SMALLの使い方

ここでは、令和5年に警察庁が調査した「自転車のヘルメット着用率」をもとに各都道府県のランキングを作成していく。
出典:警察庁「令和5年秋の全国交通安全運動の実施について」
-
自転車用ヘルメット着用率の調査結果

まずは、関数を使わずにランキング表を作成してみる。この場合は「着用率」の大きい順にデータを並べ替えればよい。
-
「着用率」の大きい順に並べ替え

続いて、「順位」の列に「1」、「2」の数値データを入力し、これらをオートフィルでコピーする。
-
順位(1、2)を入力し、オートフィルでコピー

すると、「1、2、3、・・・」の連番データを作成することができる。これを各都道府県の「順位」とみなせばよい。
-
各都道府県に順位を付けた表

たいていの場合、この方法で問題なくランキング表を作成できるが、状況によっては不具合が生じるケースもある。
今回の例をよく見ていくと、静岡県と鹿児島県の着用率はどちらも10.6%なのに、そのランキングは19位、20位という異なる順位になっていることに気付くと思う。
-
同じ数値なのに順位が異なる不具合

本来であれば、両県とも「19位タイ」として扱うべきだが、残念ながら、そうはなっていない。順位を「連番データ」で付けた際に、起こるべくして起こる不具合といえるだろう。
ほかにも、東京都、京都府、長崎県(21位~23位)、奈良県、熊本県(28~29位)、北海道、千葉県(39~40位)など、「▲▲位タイ」として扱うべきデータが散見される。
47都道府県のように数十件程度のデータであれば、これらの不具合を手作業で修正していくことも不可能ではない。しかし、数百件、数千件という規模になると、そうもいかない。このような場合に備えて、関数RANKで順位を求める方法も覚えておくとよい。