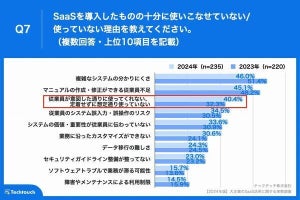
文字列データを分割したり、必要な部分だけを抽出したりするには、複数の関数を組み合わせて「文字抽出のアルゴリズム」を再現しなければならない。ということで、今回は文字列データの分割・抽出に活用できる関数を“おさらい”しておこう。これらを上手に組み合わせられるようになれば、それだけ応用範囲が広がるはずだ。
住所を「都道府県」と「それ以降」に分割する
前回の連載では、「都道府県が省略されている住所」から「都道府県」を抽出する方法を紹介した。ここまで複雑な処理でなくても、文字列の分割・抽出を行うときに「関数の複合的な知識」を問われるケースは少なくない。
-
文字列の分割や抽出に使える関数の一覧

それぞれの関数の使い方を説明する前に、前回の連載で中途半端になっていた「住所データの分割処理」を済ませておこう。以降に紹介する作業も、文字列データを分割する手法の一例として参考にして頂ければ幸いだ。
前回の連載では「住所」から「都道府県」を取得するところまで作業した。これを「都道府県」、「それ以降の住所」、「建物名・部屋番号」の3つに分割してみよう。「それ以降の住所」を抽出する方法は第39回の連載でも紹介しているが、今回の例は「最初から都道府県が省略されている住所」が混在しているのが異なる点となる。
-
変換リストをもとに「都道府県」の列を作成したデータ表

このような場合も関数SUBSTITUTEを使って「それ以降の住所」を抽出することが可能だ。具体的には、「住所」の文字列データを対象に、「都道府県」の文字を「空文字」に置き換える、という処理を行えばよい。これを関数で記述すると以下の図のようになる。
-
関数SUBSTITUTEを使った「それ以降の住所」の抽出

あとは、この関数をオートフィルでコピーするだけ。これで「それ以降の住所」を99.99%くらいの確率で正しく抽出できる。
「住所」の列には「最初から都道府県が省略されている住所」も含まれているが、特に問題なく処理できる。この場合、置換する文字(都道府県)が見つからないため、結果として「もとの住所データ」がそのまま取得されることになる。
-
オートフィルで関数SUBSTITUTEをコピーした様子

ただし、かなりの低確率ではあるが、「以降の住所」を正しく取得できないケースがある。それは「△△県営住宅」のように、住所の一部に「都道府県」と同じ名称が使用されているケースだ。
-
「それ以降の住所」を正しく取得できないケース

この場合、「都道府県」を示す文字ではない部分が「空文字」に置き換えられてしまう。第4引数に「1」を指定して、1番目の検索結果だけを置換するようにしても、上図のように思い通りに機能してくれないケースがある。非常にレアなケースではあるが、このような不具合にも備えるとなると、別のアルゴリズムを考えなければならない。
ということで、今度は「最初の数文字」に着目する方法で「それ以降の住所」を抽出してみよう。このアルゴリズムは、以下のような考え方になる。
(1)関数LENで「都道府県」の文字数(N)を調べる
(2)関数LEFTで「住所」の先頭からN文字を抽出する
(3)手順(2)の結果が「都道府県」と同じか? を関数IF調べる
(4-1)TRUEの場合:「住所」の先頭からN文字を「空文字」に置換する
(4-2)FALSEの場合:「住所」をそのまま出力する
これを関数で記述すると、以下の図のようになる。
-
IF、LEFT、LEN、REPLACEを組み合わせた方法

あとは、この関数をオートフィルでコピーするだけだ。すると、以下の図のような結果になり、全データの「それ以降の住所」を正しく取得できる。
-
オートフィルで関数をコピーした様子

ここまでの作業が済んだら「都道府県」や「住所1」のデータを「関数」ではなく、「文字列データ」に上書きしてしまってもよい。この処理は、第40回の連載で紹介した「値の貼り付け」を使って実現する。