LEFTやMIDといった関数を使って文字列データを分割することも可能だ。ただし、「関数の使い方を知っていれば十分」というケースは少なく、「どのようなアルゴリズムで文字を抜き出すか?」が重要な要素になるケースが大半を占める。その一例として、「住所」から「都道府県」を抜き出す場合を例に、考え方の基本を紹介していこう。
文字の抽出はアルゴリズム(考え方)が重要
前回の連載で紹介したLEFTやMID、RIGHTといった関数は、文字列データを分割して「新しい列」(フィールド)を作成する場合にもよく利用されている。たとえば、「住所」から「都道府県」だけを抜き出す、所属部署を「△△部」と「△△課」に分割する、といった場合などに関数LEFT、MID、RIGHTが活用できる。
ただし、単純に「関数を使えばOK」というケースは少なく、「どのような考え方に基づいて文字を抽出するか?」が重要になるケースが多い。
-
関数LEFT、MIDで文字を抽出、そのアルゴリズムと実例

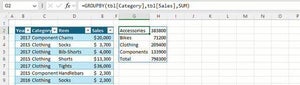
その一例として、「住所」から「都道府県」を抜き出す方法を3つ紹介してみよう。今回は、以下の図のような住所一覧を使って具体的な手順を紹介していく。
-
会員の住所一覧

最初に、「都道府県」の列を用意する。続いて、関数を使って「住所」から「都道府県」の文字を抽出していくが、「どうやって抜き出すか?」は一筋縄に解決できる問題ではない。
-
「都道府県」の列を用意

前回の連載でも紹介したように、LEFT、MID、RIGHTといった関数は「指定した文字数」だけ文字を抽出する関数となる。たとえば、「左から2文字分」とか、「4文字目から3文字分」といった文字の抽出であれば簡単に実行することができる。
一方、都道府県の文字数は「3文字」または「4文字」になるため、文字数は一律ではない。よって、関数LEFTだけで単純に解決できる問題とはならない。試しに、「住所」の先頭から3文字を関数LEFTで抽出した例を紹介しておこう。
-
関数LEFTで先頭から3文字を抽出した場合

「広島県」や「兵庫県」のように正しく「都道府県」を抽出できるケースも沢山あるが、「神奈川」や「鹿児島」のように"県"の文字が不足している・・・、といった不具合が生じてしまう。これを完璧な形にするには、一定の法則にもとづいたアルゴリズムを構築し、それを実現するように関数を記述しなければならない。その具体的な方法を3種類ほど紹介していこう。