富士通は12月12日、製造や物流などの現場に設置されたカメラ映像を認識し解析するとともに、作業指示や規則などのドキュメント情報を参照して自律的に現場改善の提案や作業レポートの作成を行うことで、人の作業を支援する映像解析型AIエージェントを開発したことを発表した。
-
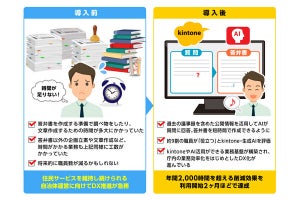
映像解析型AIエージェントのイメージ

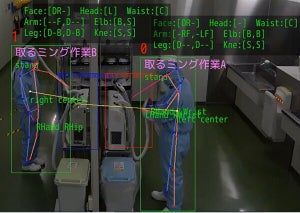
ドキュメント情報をもとに現場理解能力を拡張する自己学習技術
今回開発した技術は、マルチモーダルLLM(Large Language Models:大規模言語モデル)が映像から認識できない事象については、ドキュメントの言語情報を対応付けて学習し、AIエージェントの映像理解能力を拡張できる。
まず、ドキュメントに含まれる対象物を選択し、機械学習により対象物との距離を推定して3次元データを仮想空間上に作成。次に、ドキュメントから作成した質問と、3次元データから分かる回答を作成し、それらを学習データとしてマルチモーダルLLMをファインチューニングする。この技術によって人と物体の距離を3次元で推定することで、物流や建設の現場における安全管理や、製造現場における作業状況の生産管理システムへの自動入力などを実現するという。
空間理解能力に加え、現場固有の物体認識や人の個別作業の認識など、現場作業支援に必要なさまざまな能力をAIエージェントに追加できるようになる。
-
現場理解能力の追加学習の例