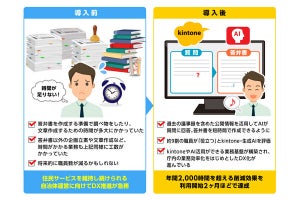
もっともらしい嘘をつく生成AI。AIが事実に基づかない情報を生成する現象は、幻覚を意味する「ハルシネーション」という言葉で表現される。OpenAIの「ChatGPT」やGoogleの「Gemini」といった生成AIは日進月歩で進化を続けているが、ハルシネーションによるリスクの不安で、本格的な活用に二の足を踏んでいる人は少なくないだろう。
厳密に言えば、ハルシネーションを起こしてしまうのは、生成AIを実現する大規模言語モデル(LLM)だ。インターネットなどから収集した大量のデータから学習したLLMは、そのデータ内の偏った情報や誤った情報も蓄えている。結果としてハルシネーションが発生してしまうことがある。言語モデルは、ある単語に対して次に続く確率が高い単語を予測しているため、「正しい情報」を常に認識して出力しているわけではない。
-
ChatGPT(GPT-3.5)のハルシネーションの例。実際には「日本DX推進連盟」という組織は存在しない

またLLMは、必ず同じ結果が出るとは限らず「冪(べき)等性がない」といった課題も抱えている。なぜ、そのようなことが起こってしまうのか。生成AI(MicrosoftのCopilot)に直接問うてみると、「私のアルゴリズムには、多様性と創造性を提供するためのランダム性が含まれています。それは私の設計の一部であり、ユーザーに対して最適な結果を提供するためのものです」と弁解された。
LLMが抱えるこれらの課題が、研究開発から商用化への進展を阻む壁となっていることは否めない。虚偽情報を利用するリスクは無視することができない。
しかし、LLMが持つ欠点を補うことができる昔ながらの技術があるという。
「LLMと『LLD』を融合することで、膨大な言語データから、再現性高く価値を生み出すことができる。LLDは、LLMのハルシネーションを抑制できる技術だ」--。
こう語るのは、20年以上の歴史を持つ徳島大学発ベンチャー 言語理解研究所のAIコンサルタント兼セールスマネージャーの尾花政篤氏。確率的に情報を出力するLLMではなく“知識を持つ"LLDとは、いったいどのような技術なのだろうか。詳しく話を聞いた。
-
言語理解研究所 AIコンサルタント兼セールスマネージャー 尾花政篤氏(役職名は取材当時)