早稲田大学(早大)は6月28日、社会経済的・文化的背景が異なる11か国の人々の経済的判断の傾向を調査し、明示的な情報に基づいたリスク回避の傾向などは国によって違いがあっても、試行錯誤を通じた学習による行動のバイアス(偏り)にはほとんど違いが見られないことを明らかにしたと発表した。
同成果は、早大理工学術院の渡邊克巳教授、パリ高等師範学校のHernán Anlló博士、同・Stefano Palminteri教授らの国際共同研究チームによるもの。詳細は、「Nature Human Behaviour」に掲載された。
ヒトを含む動物は、自分(や家族・仲間)にとってのメリットを得られる可能性を高めたり、得られるメリットを増やしたりするなど、報酬に基づく試行錯誤によってさまざまなことを学習する性質を持ち、その仕組みを「強化学習」という。言い換えれば強化学習とは、獲得した経験に基づいて行動することを可能にするメカニズムや行動のことである。
強化学習は本来、報酬を多くし、罰や損などを少なくしていくという単純なルールの上に成り立っている。しかし、文脈によっては必ずしも最適でない判断につながることが知られていた。強化学習は、医療・教育・経済・経営・政策などさまざまな分野に広範な影響を及ぼすにも関わらず、異なる社会経済的・文化的背景などが、強化学習にどのように影響するかはわかっていなかったという。
その疑問を解決するために研究チームは今回、強化学習における文脈効果を確実に捉える実験的アプローチを用いて、社会経済的・文化的に異なる11か国の人々の経済的判断の傾向を調査したとする。
例えば、以下の4点の報酬をもらえる選択肢があったとする(実際に実験で用いられたものではない)。なおカッコ内にある「期待値」とは、1回の試行で確率的に得られる値の平均値のことを指し、この値がより高くなる選択をすることが、確率的に“良い”選択である。
(A) 75%で1万円(期待値=7500円)
(B) 25%で1万円(期待値=2500円)
(C) 75%で1000円(期待値=750円)
(D) 25%で1000円(期待値=250円)
このような選択肢の「~%で~円」の部分を明示的に示して判断させる「宝くじ課題」では、「AとB」のどちらか、「CとD」のどちらかを選ばせると、当然期待値の高いAとCが選ばれる。これを何度も繰り返した後に、今度は「AとD」「BとC」をペアにして選ばせたとしても、AとCが選ばれる。ただし、このような意識的な判断の時に、報酬を得られないというリスクを回避する傾向(たとえば「BとC」をペアとした時に、期待値は低いが報酬を得られる確率は高いCを選択する傾向)は国によってかなり違っていたという。
一方、「~%で~円」の部分を明示的に示さず、試行錯誤によって学習させる「強化学習課題」も行われた。「AとB」「CとD」それぞれの組み合わせで学習し、期待値の高いAとCが選ばれるようになった後に、「AとD」「BとC」をペアとしてどちらが選ばれるのかを見てみると、「AとD」ではAを選ぶが、「BとC」だと確率的には期待値の低いCを選ぶことのほうが多くなったという。さらには、このような最適でない行動をする程度は、今回調べられたすべての国でほとんど違いが見られなかったとする。
つまり、経済的判断において、情報を説明された上で行う意識的な判断は社会経済的・文化的背景によって違いが出てくるのに対し、強化学習によって(おそらく無意識的に)形成される行動は、ほとんど影響を受けないことが示唆されたのである。
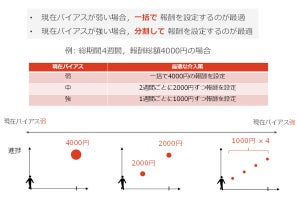
日本人はリスクを取らない傾向が強いといわれることがある。たとえば、1億円が当たる確率が1%の方が、5万円が当たる確率が50%の場合よりも、期待値という点では優れている。でも、報酬を得られないことを避ける傾向が高ければ、2番目の選択肢がより高い効用を持つように見えるかもしれない。
しかし今回の研究は、このような明確に情報が与えられた時の判断と、個人が試行錯誤の結果学んだ行動にはズレがあるということが示されているとする。研究チームはこの結果について、個人の意思決定だけではなく、医療・教育・経済・経営・政策など、より大きな枠組みを捉える時にも重要な知見となるとする。
今回の研究は、社会がグローバルな結びつきを強める中、ヒトの意思決定を支える共通の基盤としての強化学習が調べられたものになる。この研究結果は、多様な背景を持つ個人がどのように複雑な意思決定をしているのかについて明らかにし、産業界や政策立案者にも貴重な洞察を提供するものだと考えているという。また今回は、文化的・経済的背景を表すものとして“国”が一時的に用いられたが、研究チームは今後、さまざまな集団や個人差なども考慮して、ヒトの意思決定の普遍的な部分と多様性を解明していきたいとしている。