東京大学松尾研究室から誕生しLLM(Large Language Models:大規模言語モデル)の社会実装を進めるELYZAは3月12日、700億パラメータを持つモデル「ELYZA-japanese-Llama-2-70b」を開発したことを明らかにし、記者説明会を開いた。同日にデモサイトも公開している。合わせて、このモデルを含む同社の日本語LLM群を「ELYZA LLM for JP」シリーズとして提供することも発表した。
日本語ベンチマークタスクで好成績を達成
同社のLLM開発の方針は、Metaが発表したLlama2などオープンなモデルに対し日本語のデータで追加の事前学習を行い、その上で独自のデータセットを使ってPost-trainingを行うというもの。これにより日本語に強いモデルを開発している。
-
LLM開発のイメージ

今回発表したELYZA-japanese-Llama-2-70bも同様に、700憶パラメータのLlama2をベースとして同社が追加の事前学習とPost-trainingを実施している。
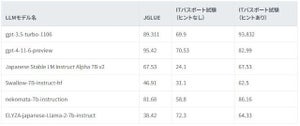
同社が開発した、LLMが指示に従う能力やユーザーの役に立つ回答を出力する性能を評価する日本語LLMベンチマーク「ELYZA Tasks 100」を実施した結果、同モデルのスコアは3.62だった。グローバルモデルと比較すると、8つのモデルの中で5位となる。これはOpenAIの「GPT-3.5 Turbo(0125)」やAnthropicの「Claude2.1」などと同程度の水準だ。なお、国内企業が公開するモデルの中では最高スコアだったとのことだ。
-
ELYZA Tasks 100スコア

また、Stability AIが提供している、LLMの対話性能を評価するための日本語ベンチマークである「Japanese MT-Bench」のスコアは7.36。グローバルモデル8つの中では7位に相当するが、数学とコーディングを除くと4位。
-
Japanese MT-Benchスコア

ELYZAの代表取締役である曽根岡侑也氏は「2023年末時点では、グローバルモデルと比較して国産モデルは大きく差を付けられていた。しかし、今回当社が開発したモデルは国内で最高水準となっただけでなく、グローバルモデルにも匹敵する性能を実現できた」と、開発の意義について説明した。
-
ELYZA 代表取締役 曽根岡侑也氏

「ELYZA LLM for JP」の提供を開始
同社はこれまで、開発したモデルを個別企業に対しそれぞれハンズオン型で提供してきた。しかし、今後はAPI(Application Programming Interface)として、広く使えるような環境を構築していくという。そのサービスが「ELYZA LLM for JP」シリーズ。
-
今後は業界や企業に特化したLLMも開発する予定

グローバルモデル以外の新たな選択肢として、金融業を含む大企業などセキュリティやカスタマイズ性を重視する企業や、自社サービスや事業にLLMを組み込みたい企業に向けて、安全性の高いAPIとして展開する。なお、本稿執筆時点で提供料金モデルや価格は未定。
-
「グローバルモデル以外の選択肢の候補に入り込みたい」と、曽根岡氏

曽根岡氏は「この場でこのようなことを言うのはおこがましいかもしれないが」と前置きをした上で、「今回の発表は日本国内でも喜ばしいニュースとなるはず。グローバルの各プレイヤーがLLMのインフラを取り合う中で日本も何か一矢報いなければならないと感じていた。私たちは腹を決めて、一矢報いるために開発を続けていくので応援してほしい」と会場に訴えかけた。同氏は感極まった様子で、熱いものがこみ上げているようだった。