ルネサス エレクトロニクスは2月22日、ビジョンAIを高速かつ低消費電力で実現できる組み込みプロセッサ技術を開発したことを発表した。
同成果の詳細は、2024年2月18日から22日まで米サンフランシスコで開催されている「国際固体素子回路会議 (ISSCC 2024:International Solid-State Circuits Conference 2024)」にて、2月21日付で発表された。
組み込み分野でも近年、AIの活用が進められつつあり、周辺環境の認識やロボットの行動判断・制御まで含めた形でのリアルタイム処理が可能な組み込み機器に対する需要が高まってきており、そのAI処理もより複雑なものへの対応を求められるようになってきている。
また、組み込み分野では、例えばSLAM(Simultaneous Localization and Mapping)のような行動の判断や制御において必ずしもAIを用いないアルゴリズムの活用ニーズも根強くあり、AIの活用と、そうした非AIのアルゴリズム処理の両方を高性能で行えるSoC/MPUが実用的な面では必要とされるようになっているという。
実際にそういった処理をすべて賄うだけの性能を持たせた組み込みAI MPUの場合、数十TOPSから100TOPSクラスのピーク性能が求められることとなるが、従来のAIアクセラレータでは発熱量が大きくなってしまい、消費電力10W以下でファンレス化が求められるロボットをはじめとする機器に搭載できないという課題があったとする。さらに、非AI側における協調動作などの処理も求められるため、一般的な組み込みCPUでは十分なリアルタイム性能が発揮できず、これらをリアルタイム性を持たせて処理できるようになるためには少なくとも現状の10倍以上に性能を向上させる必要があるともする。
-
エッジ分野でのAI活用が進むことでAI処理と非AIアルゴリズム処理の両方で性能向上が求められるようになってきたが、発熱の問題などもあり電力消費量を抑える必要もある (資料提供:ルネサス、以下すべて同様)

第3世代DRP-AI技術で理想的な枝刈り処理を実現
こうした市場からのニーズに対し同社は、軽量化したAIモデルを効率よく処理できる動的再構成プロセッサ(Dynamically Reconfigurable Processor:DRP)ベースのAIアクセラレータ(DRP+MACで構成)を開発したほか、CPUなど各種IPを協調動作させることでリアルタイム処理を実現するヘテロジニアスアーキテクチャの2つの技術を開発することで、14nmプロセスベースの試作チップで従来比で最大16倍となる130TOPSの処理性能、ならびに最大23.9TOPS/W(0.8V動作時)の電力効率を達成したとする。
-
ISSCC 2024にて発表された開発技術を元にしたハードウェアアーキテクチャのイメージ。AI処理はDRP-AIが、非AI処理をDRPが、そして汎用処理をCPUがそれぞれ担う

今回のDRP-AIは、同社が2022年12月に発表したDRP-AI技術をベースに改良が施された第3世代に当たるもの(もともとの2022年12月発表のDRP-AIも第3世代に位置づけられている。第1世代はRZ/V2LならびにRZ/V2Mに搭載されたもの。第2世代は研究レベルにとどまりMPUへの搭載が見送られたという)。
AIのメモリ消費量の削減や処理効率向上技術の1つとして、認識精度の影響が少ない演算部分を読み込まなくする「枝刈り」があるが、不規則に発生する認識精度に影響しない枝刈りされたデータは、行列内のランダムな場所に発生するため、効率よく枝刈りをすることが難しいという課題があった。あえて規則を設けて処理するという手法もあるが、ランダムに枝を刈る方法に比べて枝刈りを上手くできないという問題もあったほか、不規則であっても、並列演算器に0と1の情報が同時に入ると、不要なはずの0の演算も一緒に行わざるを得ないという問題もあり、既存のAIプロセッサでは枝刈りの効果を十分に得ることができなかったという。
-
枝刈りで演算量を減らせることは以前から知られていたが、それでも課題があった。それを今回、DRP-AIを活用する形で、枝刈りモデルの高速化を実現した

そこで今回のDRP-AIでは、枝刈りモデルで適切に高速化処理する手法「フレキシブルN:M枝刈り手法」を採用。これは、重み行列を最適なより小さな重み行列のグループに分割。重要な0にしてはいけない意味のあるノードだけを集めて、圧縮してやることで、0の演算を無駄なく演算できるようにするもので、小さな重み行列グループ化や、グループごとの圧縮モデルサイズ(N)の値については、コンパイラで処理する際に、自動的に最適な値にしてくれるということで、開発者がその点を意識せずに、全体にどの程度の0を用いるか、枝刈り率を細かく設定してやることが可能な点が特長で、行列のブロックごとにNを切り替えてやることで、細かな枝刈り率を実現しつつ、それをつなぎ合わせていくことで、事実上、好きな枝刈り率を調整したNを実現できるようになると同社では説明する。また、どれくらい枝を刈るかについては、認識の精度に応じて変わってくるため、用途や必要に応じた最適化を図ることも可能で、それによる低消費電力化や高効率化が可能になり、理想的な枝刈り処理ができるようになるとする。
既存の並列プロセッサによる枝刈りはサイクル数自体は減らすことができなかったが、DRP-AIでは重みデータ行列をより小さな単位に再構成することで演算サイクル数の調整を可能としたことにより、サイクル数の削減と消費電力の削減を実現した



DRP-AI、DRP、CPUを協調動作させるヘテロジニアスアーキテクチャ
AI処理の高速化だけで考えれば、DRP-AIの高性能化だけで良いが、実際にロボットの制御などを行おうとすれば、AI部と非AI部のマルチスレッド処理が必要となる。
こうした非AIの制御にはDRP-AIではなく、その元となっているDRPの方が得意である。DRPは、必要な演算器やメモリをサイクルごとに切り替えて、最適なデータ処理を可能にする技術であり、無駄な回路を動かさずに済むため、低電力化や高速化が可能になるほか、ストリーミングの処理をパイプライン上に流す形での処理のためミスヒットが起きないというメリットもあり、安定したサイクル数での処理が可能なため、ロボットに求められるようなリアルタイム処理に向いている。
-
DRPの概要。サイクルごとに利用する演算器やメモリを切り替えて最適なデータ処理を実現するため、消費電力を抑えながら、高速な処理が可能となる

また、ロボットの制御には複数のアルゴリズムを組み合わせる必要があるが、そうしたアルゴリズムの切り替えについてもDRPでは1msで切り替えが可能であることから、相性が良いと同社では説明する。
例えば画像処理を行う場合、AI部分が高速化しても、その前後段の処理が高速化しなければ、そこがボトルネックとなる。その部分の処理をDRPに行わせれば、全体的な高速化を図ることが可能となるという。同社の試験では、AI以外の処理部分をDRPに置き換えることで、置き換えない場合と比べて6.5倍の高速化を実現できることを確認したという。また、画像認識のライブラリの1桁高速化やSLAMアプリケーションの実行では組み込みCPU単独動作に比べて約17倍の高速化、ならびに消費電力の1/12程度への低減を確認したとする。
-
画像認識処理におけるDRPの効果。非AI処理部が高速化でき、組み込みCPUで処理した場合と比べて6.5倍の高速化を実現できたとする

14nmの試作チップはヒートシンク不要で処理可能であることを確認
ルネサスでは、これらの技術を盛り込んだ14nmプロセスによる試作チップを実際に製造。0.8V電源電圧時で1Wあたり23.9TOPSの電力効率を達成したこと、ならびに主要なAIモデルを動作させた際の電力効率1Wあたり10TOPSを実証したとする。
-
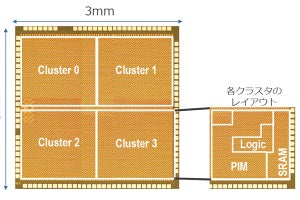
14nmプロセスを用いて製造された試作チップの概要

また、その際の発熱も従来の同程度のAIアクセラレータではヒートシンクとファンでの冷却が必要であったが、ヒートシンクもファンもない状況で同程度(50℃強程度)の温度にでき、動作可能であることも確かめられたとしている。
-
試作チップを用いたAIアプリを走らせた際の温度。競合のSoCはヒートシンク+ファンの構成、ルネサスが開発したチップはヒートシンクもファンもない状況ながら同程度の温度で同程度の性能を実現できていることが確認できたという

なお、ルネサスではこれらの技術を将来のRZ/Vシリーズに適用していくことで、ロボティクスやスマート市場などさまざまな産業における自動化ニーズの拡大に対応していきたいとしている。