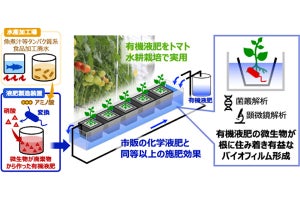
産業技術総合研究所(産総研)は9月29日、視覚情報から物体間に働く力を想起することのできるAI技術を開発したことを発表した。
同成果は、産総研 インダストリアルCPS研究センター オートメーション研究チームの花井亮主任研究員、同・堂前幸康研究チーム長、同・Ixchel Ramirez主任研究員、同・牧原昂志リサーチアシスタント、同・原田研介特定フェロー、産総研 人工知能研究センターの尾形哲也特定フェローらの共同研究チームによるもの。詳細は、米国ミシガン州デトロイトで10月1~5日にわたって開催のロボット分野の国際会議「IROS 2023」にて発表の予定。
現在の技術の視覚センサだけでは、ロボットは見ただけでその物体の硬軟や崩れやすさなどを見極めることは困難であり、力覚センサや触覚センサなどが用いられているが、その場合は触っただけで崩れてしまうような物体には対応できなかった。
それに対し、視覚から運動のダイナミクスに関するような別の感覚の想起(クロスモーダル)を簡易に実現できれば、安価なセンサから人間のような行動計画を実現することが可能となるという。そこで研究チームは今回、画像から物体間にかかる力の分布を想起するAI技術を開発、ロボットへの応用の可能性を探ることにしたとする。
-
視覚情報から物体間に働く力を想起するAI技術とロボット作業への応用(出所:産総研Webサイト)

今回の技術では、物体同士が接触することで生じる力を画像から推定することが可能で、実験ではカゴの中にある物体が周囲の物体と接触することで生じる力の大きさが、色を用いて視覚的に表現された。また対象物には、学習に使われていない未知物体も含まれており、これは今回の技術がさまざまな日用品に対する汎化性能を獲得できる可能性が示されているとした。
さらに今回の技術は学習がシミュレーション内で行われ、現実環境に適応するにあたって追加学習の必要がない「ゼロショット転移」が採用されており、画像1枚(カメラ1台)から日用品の物体間にかかる力分布をリアルタイムに推定することが可能とした。
-
提案手法により、画像から物体間に働く大まかな力分布を想起した様子(緑から赤になるほど相対的に大きな力がかかっている)。提案手法は、(a)寄りかかった箱とカゴとの接触位置に力を想起(カゴ側面からの接触力は小さい)、(b)円筒の缶とカゴ底面の間に細い線状領域での接触を予測、(c)積み重なった物体間(りんごとオレンジの間など)の接触位置にも力を想起している。今回の技術は、(d・e)未知物品に対しても同様の想起が可能(上:入力画像、下:想起された3次元の力分布)。※原論文の図を引用・改変したものが使用されている(出所:産総研Webサイト)

なお視覚情報に対し、正確な力分布を得ることは現実世界では困難のため今回の研究では、物理シミュレータが用いられ、ランダムに配置される日用品の3Dモデル間にかかる「物体間に働く力」を物理演算する仕組みを採用。しかし、物理演算は正確に現実世界の物理現象を再現しているわけではないため、正確な力の量を推定しようとすれば、シミュレーションと現実のギャップ(メインギャップ)を埋めるために膨大な労力を必要としてしまうことが課題だった。
そこで今回は、正確な物体の力の量ではなく物体間の大まかな力の分布に着目し、シミュレータ上で仮想経験データを生成することで視覚的情報を入力、物体間の力分布を出力する深層学習モデルの訓練が行われた。
-
視覚から物体間の力の分布を推定する学習方法。※原論文の図を引用・改変したものが使用されている(出所:産総研Webサイト)

モデルはResNet50をエンコーダとし、ResNetを基に設計したデコーダと組み合わせることで構成した結果、ゼロショットでの実カメラへの適用が実現。今回は通常とは逆で、「現実では得難い経験」を積ませることで、現実世界での経験を補完した点も技術的に重要な成果とした。
またロボットによる物体操作の計画問題に対し、今回の技術が応用されたところ、視覚情報のみから人間のような丁寧な物体操作方法を計画できたという。
-
ロボットマニピュレーションの計画問題への応用。(a)提案手法がない場合。物体を持ち上げる際に上にあるほかの物体を落としてダメージを与えている。(b)提案手法がある場合。上の物体のダメージが少ないような丁寧な操作が実現できている。※原論文の図を引用・改変したものが使用されている(出所:産総研Webサイト)

また、これまでに産総研の牧原リサーチアシスタントらは、力の分布と同じような考え方に基づき物体の柔らかさを推定。少数の商品の3Dモデルに対し、手動で与えた物体の柔らかさを表すマップを貼り付け、シミュレーション上で大量にデータを生成することで、深層学習モデルに視覚(距離画像センサによる深度画像)から得られる物体形状と柔らかさの関係を学習させた。これにより、形状から物体の種類が推定できる場合にシーン中の柔らかさの分布を予測できるようになったとした。
-
視覚から柔らかさの想起。(左)シミュレータ上で深度画像と物体の柔らかさの分布からなる仮想経験データを構築。(右)深度画像から柔らかさを予測するモデルを学習(黄から緑、青と変わるほど柔らかい)(出所:産総研Webサイト)

今回のAIをロボットに適用したところ、物体把持に関する最新手法であるDex-Netと比較して、作業成功率は同等かつ把持対象の物体のつぶれは70%以上抑えられることが確認された。また、逆に形状だけから判断すると把持できない状況で、柔らかさを利用して周辺のものを変形させて押しのけて把持するという人間らしい行動をロボットが取ることにも成功したとする。
-
柔らかい周辺物体を押しのけて対象物を把持(出所:産総研Webサイト)

このような視覚から別の感覚を想起する技術は、安価なセンサにより人間らしい器用な行動計画を実現するため、工場や物流倉庫におけるロボットによる物体操作や、家庭用スマートロボットへの展開が期待されるとした。またシミュレーションによる経験データの作り方・与え方を工夫することで、自然環境において崩れやすそうな場所を見つけるという応用も想定される。将来的には自動運転における危険予知や衛星画像からの災害予知など、広い分野への適用を目指すとした。