エクサウィザーズは9月20日、画像の内容を基に、その状況を対話型で説明する生成AIモデル「exaBase Visual QA」を開発したと発表した。
同モデルの特徴は、画像を認識する一般的な生成AIモデルでは出力するのが難しいとされている複雑な画像について、その危険性などの内容を的確に文字情報として出力することに着目していること。
人が画像を見た時にどこに注目するのかを生成AIモデルに学習させることに取り組んだ結果、人が直感的に認識可能な、画像内の危険性や違和感といった状況を高精度で解釈することが可能になったという。同ソリューションを実装したシステムとチャットボットのように対話することで、状況を説明する文章を生成することができる。
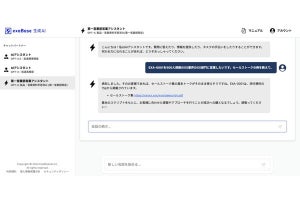
具体的には、以下のような画像に対して「潜在的な危険性はありますか」と入力することで、「作業員がバランスを崩したり足場が崩れたりすると落下につながる。作業員は金属棒を接続するために電動工具を使用しており、工具が滑ると負傷する可能性がある。適切な安全予防措置を講じるべきである」といった文章を生成する。システムの実装時には長文を出力されるものの、ChatGPTを用いて必要な部分にフォーカスした要約が可能だ。
-
exaBase Visual QAのプロトタイプ画面(現時点で文章の入出力は英語だが、翻訳機能を利用することで各国語に対応できる)

なお、同社での評価実験において、他の商用利用可能なモデルより最大で1割弱高い解釈の精度を持っていることが確認されており、同様の精度のモデルと比べてモデルのサイズも小さく、推論の実行や生成の速度も高速であるとの特徴も兼ね備えている。
また、同ソリューションはオープンソースの生成AIモデルをベースに開発しており、同社が追加学習を実施している。そのため、すぐに利用が可能であることに加え、個別の分野のデータを学習し、設定を調節する「ファインチューニング」を同社側で行うことで、「建設現場などでの作業における危険性の判定」や「保育園や学校など、多様な人の動きがある場所での状況把握」といった特定の分野での精度を向上させることも可能となっている。