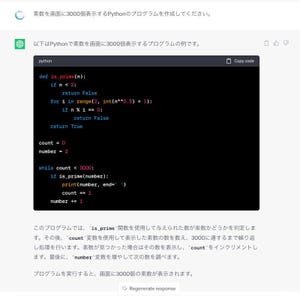
米Googleが7月1日にプライバシー・ポリシーを更新し、オンラインまたは他の公的なソースにおいて一般に公開されている情報を、AIモデルのトレーニング、「Bard」やCloud AIの機能の開発などに使用することを追加した。
「コンプライアンスおよび規制当局との協力」の「研究開発」で、サービスの改善、新しいサービスや機能、テクノロジーを開発するための情報使用に関する内容が以下のように変更された。
たとえば、GoogleのAIモデルのトレーニングのほか、Google翻訳、Bard、CloudのAI機能などサービスや機能の構築に、一般公開されている情報を利用します。
変更前は「Googleの言語モデル」だったトレーニングへの使用の範囲を「GoogleのAIモデル」に拡大し、実験的な提供を開始したBardなどが含まれることを明確にしている。GoogleはAI(人工知能)/ML(機械学習)の開発におけるデータ利用に関して、透明性を通じて信頼を築くことを重視しており、今回のプライバシー・ポリシーの変更は、プライバシーを保護しつつ、AI技術の開発を推進するバランスを保つ試みと見られている。

しかし、生成AIの開発を巡る競争が激化する中、公開されている情報であっても慎重な使用を求める声が広がっている。
今年に入って、TwitterやRedditがAPIのアクセスを制限し、API使用料金の負担を重くする変更を実施し、アプリ開発者やユーザーを困惑させている。その背景にはAI開発競争がある。AIトレーニング目的のデータ収集やWebスクレイピングをポリシーで禁じるだけではなく、他社によるデータの自由な取得を防ぐための抜本的な対策に踏み出した。しかし、それによってWeb全体で柔軟に情報を共有できるTwitterやRedditのコアと呼べるユーザー体験が損なわれ、利用が減少する悪循環に陥っている。また、著作権のあるコンテンツが商業的なAIのトレーニングに使用されることで不当な利益損失を被る可能性を指摘するクリエイターがいるなど、AIトレーニングにフェアユースの原則を適用することに関して不確実な部分も多い。それが、AI開発企業の自主規律ではなく、トレーニングデータの収集・使用に関する規制法案を求める声を後押ししている。